
ABSTRAK
Prediksi akurat curah hujan ekstrem akibat siklon tropis (TCER) sangat penting untuk mitigasi bencana di wilayah pesisir. Namun, hal itu tetap menjadi tantangan berat karena interaksi rumit di antara faktor meteorologi multiskala dan ketidakseimbangan data yang melekat. Studi ini menyajikan kerangka kerja pembelajaran mesin (ML) yang dapat ditafsirkan yang ditujukan untuk memprediksi kejadian dan besarnya TCER di Guangxi (GX), Tiongkok. Kerangka kerja tersebut mengintegrasikan tiga algoritma pembelajaran terbimbing, yaitu XGBoost, Random Forest, dan AdaBoost, bersama dengan teknik pemilihan fitur dan metode yang dapat dijelaskan. Sebanyak 202 eksperimen dilakukan untuk mengevaluasi kinerja kerangka kerja secara komprehensif. Optimasi Algoritma Genetika (GA) dan penjelasan aditif Shapley (SHAP) digunakan untuk mengidentifikasi subset fitur yang optimal dan mengukur kontribusi setiap variabel secara akurat. Hasil penelitian menunjukkan bahwa model XGBoost yang dioptimalkan menunjukkan kinerja yang luar biasa, mengintegrasikan 18 prediktor di seluruh variabel dinamis, termodinamika, kelembapan, dan prekursor, dengan Skor Ancaman sebesar 0,41 untuk klasifikasi kejadian TCER dan Skor Ancaman sebesar 0,49 untuk regresi besaran curah hujan, mengungguli data ansambel TIGGE dalam studi kasus topan Chaba (2022) dan Doksuri (2023). Analisis SHAP mengungkapkan bahwa Jarak ke Jalur adalah faktor yang paling penting untuk kejadian TCER. Analisis ini juga mengungkap keberadaan interaksi nonlinier. Misalnya, peningkatan geser angin vertikal, kondisi termal yang menguntungkan, gerakan menaik, dan aktivitas subtropis yang tinggi dapat secara substansial memperkuat kemungkinan TCER jika digabungkan dengan akumulasi kelembapan tingkat rendah. Selain itu, variabel yang mengalami jeda waktu dan variabel yang mengalami evolusi waktu menunjukkan kemampuannya untuk menangkap sinyal pendahulu kejadian TCER, seperti akumulasi kelembapan, penyesuaian sirkulasi, dan perubahan intensitas topan, yang menyoroti keefektifan model dalam mempertimbangkan faktor-faktor ini. Oleh karena itu, studi ini menunjukkan potensi besar ML dalam meningkatkan prediksi TCER sambil mempertahankan interpretabilitas fisik. Selain itu, studi ini menawarkan referensi berharga untuk mengatasi masalah ketidakseimbangan dalam bidang penelitian serupa.
1 Pendahuluan
Siklon tropis (TS) sering kali menyebabkan hujan ekstrem, yang mengakibatkan berbagai dampak yang mahal, dahsyat, dan berbahaya seperti banjir yang meluas, banjir bandang, dan tanah longsor, yang menimbulkan kerusakan properti dan korban jiwa yang besar di wilayah pesisir (Chen dan Ding 1979 ; Dong et al. 2010 ; Tao 1980 ). Misalnya, Topan Doksuri (2023) membawa hujan ekstrem yang meluas di seluruh Tiongkok, dengan beberapa wilayah mengalami curah hujan yang memecahkan rekor, yang memengaruhi 2,95 juta orang dan mengakibatkan kerugian ekonomi langsung sebesar 14,95 miliar yuan Tiongkok. Demikian pula, Topan Haikui (2023) berdampak berkepanjangan di Tiongkok selatan, mencatat rekor curah hujan baru di Guangdong, Hong Kong, dan Makau, yang menyebabkan 6 kematian dan kerugian ekonomi langsung sebesar 16,66 miliar yuan Tiongkok. Oleh karena itu, prediksi yang akurat dan tepat waktu terhadap peristiwa ekstrem seperti itu sangat penting untuk pencegahan dan mitigasi bencana dan merupakan tantangan ilmiah mendasar karena frekuensi dan intensitas peristiwa ekstrem ini diperburuk oleh perkembangan cepat pemanasan global (Chen 2010 ; Seneviratne et al. 2021 ).
Sejumlah penelitian sebelumnya telah menyoroti bahwa kejadian hujan ekstrem yang disebabkan oleh TC (TCER) biasanya merupakan hasil dari pertemuan berbagai proses fisik dalam spektrum skala spasial dan temporal yang luas. Kejadian-kejadian ini dapat dipengaruhi oleh berbagai variabel, termasuk variabel permukaan yang mendasarinya, variabel lingkungan, dan variabel khusus TC (misalnya, Cai et al. 2023 ; Dong et al. 2010 ; Jiang et al. 2018 ; Qiu et al. 2019 ). Beberapa penelitian telah menekankan peran penting yang dimainkan oleh karakteristik TC itu sendiri. Variabel seperti lintasan TC, intensitas TC, kecepatan transisi badai, dan geser angin vertikal (VWS) sangat penting dalam membentuk distribusi dan besarnya curah hujan yang disebabkan oleh TC (Corbosiero dan Molinari 2002 ; Lonfat et al. 2004 ). Misalnya, rata-rata curah hujan maksimum TC terletak di kuadran depan, namun bervariasi dengan intensitas TC (Lonfat et al. 2004 ). Selain itu, TC dengan kecepatan gerakan yang lebih lambat dapat memperpanjang periode dampak TC, sehingga meningkatkan kemungkinan kejadian TCER (Cai et al. 2023 ; Chen dan Xu 2017 ; Chien dan Kuo 2011 ; Liu dan Wang 2020 ; Su et al. 2012 ; Wu et al. 2022 ). Selain itu, VWS yang lebih tinggi mendorong perkembangan asimetri yang lebih besar dalam curah hujan yang disebabkan oleh TC (Chan et al. 2019 ; Chen dan Fang 2012 ; Chen et al. 2006 ; Corbosiero dan Molinari 2002 ; Wen et al. 2017 , 2019 ; Xu et al. 2014 ; Yu et al. 2015 , 2017 ; Yuan et al. 2010 ). Selain itu, signifikansi fitur permukaan yang mendasarinya (misalnya, pegunungan, garis pantai) dalam pembangkitan kejadian TCER telah ditekankan oleh banyak penelitian (Deng dan Ritchie 2020 ; Jiang et al. 2018 ; Liu et al. 2022 ; Qiu et al. 2019 ). Topografi tidak hanya mengalihkan jalur TC tetapi juga meningkatkan kejadian TCER di daratan melalui efek gabungan dari pengangkatan dan pemblokiran topografi (Huang et al. 2012 ; Jiang et al. 2018 ; Liu et al. 2022 ). Lebih jauh lagi, intensitas TCER juga bergantung pada kondisi lingkungan, termasuk musim panas, perubahan di daerah subtropis Pasifik Utara bagian barat (WNPSH), kondisi uap air, divergensi/konvergensi angin, kondisi dinamika vertikal, dan intrusi udara dingin (Chan et al. 2004) .; Dong dkk. 2010 ; Yan dkk. 2022 ; Zhang dan Chen 2012 ; Zhao dkk. 2021 ; Zhou dan Wu 2019 ). Kemunculan dan intensitas TCER sering kali bergantung pada keberadaan kondisi lingkungan dinamis yang lebih menguntungkan, seperti uap air sekitar, energi termal, dan energi potensial baroklinik, saat TC berinteraksi dengan medan lingkungan selama pendaratan (Dong dkk. 2010 ; Yan dkk. 2022 ; Zhao dkk. 2021 ). Studi-studi ini telah memberikan wawasan berharga bagi para peramal cuaca dalam memahami pembentukan dan keberlanjutan peristiwa TCER. Kendati demikian, perubahan dalam variabel-variabel ini di berbagai skala spasial dan temporal dapat terjadi bersamaan dan berinteraksi secara nonlinier, yang menyebabkan perubahan dalam hubungan antara faktor pendorong tertentu dan TCER (Gao et al. 2017 ; Grandey et al. 2014 ; Krishnaswamy et al. 2015 ; Lin et al. 2023 ), sehingga menimbulkan tantangan dan kesulitan yang cukup besar dalam menganalisis secara simultan kemungkinan hubungannya dengan faktor-faktor potensial dan secara akurat memperkirakan kejadian TCER di masa mendatang.
Meskipun pekerjaan substansial telah dilakukan pada peramalan presipitasi menggunakan kedua metode statistik klasik (seperti ekstrapolasi dan regresi bertahap) dan model prediksi cuaca numerik (NWP) (Huang et al. 2018 ; Ren et al. 2018 ; Ding et al. 2020 ), yang telah membentuk fondasi peramalan curah hujan untuk tujuan operasional di sebagian besar negara, prediktabilitas operasional curah hujan ekstrem saat ini masih terbatas karena kompleksitas mekanisme dan representasi yang tidak memadai dari kemungkinan variabel yang berkontribusi terhadap presipitasi ekstrem (Donoho 2000 ; Fan dan Li 2006 ; Johnstone dan Titterington 2009 ; Wang et al. 2012 ; Gao et al. 2013 ; Ding et al. 2020 ). Selain itu, secara luas diakui bahwa kolinearitas sering muncul ketika beberapa faktor dimasukkan ke dalam pelatihan model (Tong et al. 2019 ), sementara metode pembelajaran mesin memiliki kemampuan yang kuat untuk menangani masalah nonlinier (Breiman 2001 ). Hasilnya, penelitian di bidang ini yang memanfaatkan pendekatan pembelajaran mesin (ML) telah secara aktif dilakukan secara global selama beberapa dekade terakhir (Herman dan Schumacher 2018 ; Lin et al. 2023 ). Hill et al. ( 2020 ) menunjukkan bahwa penggunaan algoritma hutan acak (RF) dapat meningkatkan prakiraan cuaca buruk operasional untuk seluruh periode 1–3 hari ke depan di seluruh Amerika Serikat yang bersebelahan. Jalal Uddin et al. ( 2022 ) mengusulkan model prediksi indeks curah hujan ekstrem bulanan baru untuk Bangladesh dan menemukan bahwa menggabungkan parameter atmosfer dan telekoneksi laut-atmosfer dapat membantu dalam memprediksi indeks curah hujan ekstrem saat menggunakan algoritma RF. Lin et al. ( 2023 ) menggunakan berbagai algoritma ML untuk mengeksplorasi hubungan dengan curah hujan ekstrem bulanan di enam wilayah Amerika Serikat, dan untuk memprediksi intensitas, frekuensi, dan kejadian bulanan curah hujan ekstrem. Grazzini et al. ( 2024 ) mengembangkan model prakiraan berdasarkan algoritma RF untuk memprediksi kejadian presipitasi ekstrem di Italia utara dan tengah. Mereka berhasil mengidentifikasi kondisi atmosfer yang mendukung kejadian presipitasi ekstrem, mengklasifikasikan kondisi ekstrem tersebut ke dalam berbagai jenis (Grazzini et al. 2020 ), dan akhirnya meningkatkan prediksi kejadian presipitasi ekstrem (Grazzini et al. 2024 ). Zhu dan Aguilera ( 2021 ) mengungkapkan bahwa algoritma RF merupakan pendekatan ML yang efisien yang mampu memprediksi presipitasi TC secara akurat dan mengidentifikasi variabel kunci untuk memprediksi presipitasi TC.
Namun, mayoritas penelitian sebelumnya terutama berfokus pada presipitasi ekstrem secara umum, dengan relatif sedikit perhatian yang diberikan pada peristiwa TCER. Selain itu, topografi berbagai wilayah bervariasi secara signifikan, yang memerlukan pertimbangan cermat terhadap variasi topografi spasial sebagai variabel fitur utama. Secara luas juga diakui bahwa menggabungkan lebih banyak faktor tidak serta merta memastikan kinerja model yang lebih baik (Tong et al. 2019 ). Selain itu, ada kekurangan analisis ML yang memadai yang bertujuan untuk mengidentifikasi pendorong utama yang memainkan peran penting dalam terjadinya peristiwa TCER. Dari perspektif ini, studi ini secara komprehensif memeriksa berbagai metode pemrosesan data yang tidak seimbang, teknik pemilihan fitur, dan tiga algoritma ML untuk mengembangkan model klasifikasi dan regresi untuk memprediksi terjadinya dan besarnya peristiwa TCER, masing-masing. Model-model ini didasarkan pada beragam variabel, termasuk variabel skala besar, variabel lokal, variabel khusus TC, dan variabel topografi. Karena keterbatasan sumber daya komputasi operasional, analisis kami berfokus pada provinsi Guangxi (GX), sebuah wilayah di bagian barat Tiongkok selatan. Daerah ini memiliki topografi yang beragam dan sangat rapuh terhadap TC, yang dapat menyebabkan bencana yang signifikan. Lu et al. ( 2021 ) dan Zhang et al. ( 2023 ) telah menunjukkan bahwa wilayah ini adalah salah satu dari tiga provinsi di Tiongkok dengan kerugian ekonomi rata-rata tahunan tertinggi yang disebabkan oleh TC, yang menimbulkan ancaman besar bagi populasi dan ekonomi lokal. Antara tahun 1981 dan 2020, total 149 TC mempengaruhi GX, termasuk 730 kejadian TCER (Cai et al. 2023 ), yang menunjukkan jumlah kasus yang cukup dan memberikan representatif untuk penelitian ini. Penelitian ini memiliki dua tujuan utama. Pertama, untuk mengembangkan model klasifikasi biner yang bertujuan untuk memberikan pemahaman yang komprehensif tentang faktor-faktor fisik utama yang memengaruhi terjadinya kejadian TCER di GX. Hal ini dicapai melalui pemilihan variabel penjelas menggunakan metode validasi yang berbeda, yang merupakan langkah penting dalam menjelaskan proses fisik yang mendasari yang mengarah ke kejadian TCER dan memastikan akurasi prediktif model. Kedua, mengembangkan dan membandingkan beberapa model, serta melakukan studi kasus untuk menyediakan model regresi yang lebih tepat dalam memprediksi total volume kejadian TCER.
Artikel ini disusun sebagai berikut. Bagian 2 memberikan deskripsi terperinci tentang kumpulan data yang digunakan, pemilihan prediktor, dan metodologi ML yang digunakan. Di Bagian 3 , kami menyajikan kinerja model klasifikasi yang berfokus pada kemunculan peristiwa TCER dan model regresi untuk memprediksi besarnya TCER, beserta analisis interpretabilitas fisiknya. Model regresi dievaluasi lebih lanjut melalui studi kasus dua peristiwa TC historis ekstrem dalam beberapa tahun terakhir. Kesimpulan dan pembahasan disajikan di Bagian 4 .
2 Data dan Metode
2.1 Data
TC yang memengaruhi GX diekstraksi dari kumpulan data jalur terbaik dari Shanghai Typhoon Institute of China Meteorological Administration (Lu et al. 2021 ). Dalam studi ini, TC yang bergerak menyamping dan TC yang mendarat dari tahun 1981 hingga 2020 dipilih, karena keduanya berpotensi memicu curah hujan ekstrem di wilayah tersebut. Hanya TC yang diberi nama resmi oleh badan meteorologi yang dipertimbangkan, sehingga totalnya menjadi 149 TC (dengan jalurnya diilustrasikan pada Gambar 1a ) yang tersedia untuk analisis dan pemodelan.

Curah hujan harian yang disebabkan oleh TC diekstraksi dari alat pengukur hujan di 91 stasiun pengamatan Tiongkok di provinsi GX (seperti yang ditunjukkan pada Gambar 1a ) dari tahun 1981 hingga 2020, yang bersumber dari Pusat Layanan Data Meteorologi Tiongkok. Dengan menggunakan metodologi yang sama seperti Cai et al. ( 2023 ), setelah menghilangkan sampel data dengan curah hujan harian kurang dari 0,1 mm, intensitas curah hujan pada persentil ke-99 dari periode iklim terkini (1991–2020) ditetapkan sebagai ambang batas ekstrem untuk setiap stasiun. Curah hujan harian di stasiun tertentu dalam radius 500 km dari pusat TC tertentu dianggap sebagai curah hujan yang disebabkan oleh TC ini. Curah hujan yang disebabkan oleh TC yang melebihi ambang batas tersebut di stasiun tersebut dianggap sebagai kejadian TCER, dan hari kejadian TCER paling signifikan untuk setiap TC ditetapkan sebagai hari TCER maksimum (hari TCMDR). Variabel curah hujan target di sini untuk model ML mencakup rangkaian waktu tabular yang diperoleh dari kejadian biner (di mana 1 menunjukkan terjadinya peristiwa TCER dan 0 menunjukkan ketidakhadirannya), serta total curah hujan harian dari peristiwa TCER di setiap stasiun. Sebanyak 730 peristiwa TCER diidentifikasi di antara 41.669 peristiwa curah hujan yang disebabkan oleh TC selama 119 hari ketika peristiwa TCER terjadi dari tahun 1981 hingga 2020. Untuk memverifikasi model regresi di Bagian 3.2.2 , kami juga menggunakan data curah hujan yang diprediksi, yang disediakan oleh dataset International Grand Global Ensemble (TIGGE) dengan grid 0,125° × 0,125° dan waktu tunggu 12 jam selama Topan Chaba (No. 202203) dan Topan Doksuri (No. 202305) untuk studi kasus.
Variabel atmosfer diperoleh dari versi kelima model analisis ulang European Centre for Medium-Range Weather Forecasts (ECMWF) (ERA5; Hersbach et al. 2020 ), dengan grid 0,25° × 0,25° dan resolusi waktu 6 jam. Khususnya, tujuan kami adalah mengembangkan model ML dengan mengekstraksi seri variabel jangka panjang untuk mengidentifikasi faktor-faktor utama untuk kejadian TCER dan untuk membangun model prediktif yang lebih akurat. Hanya setelah menyetel model secara menyeluruh, kami akan menggunakan variabel prakiraan dari model prediksi cuaca numerik (NWP) untuk menjalankan model ML untuk memprediksi kejadian TCER. Berdasarkan pemahaman fisik, kami memilih banyak variabel atmosfer sebagai prediktor kejadian TCER, termasuk kelembaban spesifik ( q ) pada 925, 850, dan 700 hPa; Angin U ( u ) pada 200 hPa; Angin V ( v ) pada 925, 850, dan 200 hPa; tinggi geopotensial ( hgt ) dan Omega ( w ; penurunan skala besar) pada 500 dan 200 hPa; divergensi angin ( div ) pada 200 hPa; vortisitas ( vor ) pada 925 dan 850 hPa; adveksi vortisitas ( vor_adv ) pada 500 hPa; suhu potensial ekivalen ( thetae ) dan gradiennya ( delta_thetae ) pada 850 dan 700 hPa. Selain itu, variabel transpor uap air seperti komponen zonal ( qu ) dan meridional ( qv ) dari transpor uap air, kecepatan angin transpor uap air ( qwspd ), dan divergensinya ( qdiv ) pada 925 dan 850 hPa dipertimbangkan. Semua variabel ini diinterpolasi ke lokasi stasiun menggunakan metode interpolasi linier untuk tujuan pencocokan stasiun. Selain itu, geser angin vertikal ( vws ), dihitung sebagai perbedaan kecepatan angin rata-rata antara 200 dan 850 hPa dalam area 5° × 5° yang berpusat di pusat TC (Xiao et al. 2021 ), bersama dengan komponen zonal ( vws_u ), meridional ( vws_v ) dan arahnya ( vws_direction ) juga disertakan.
WNPSH adalah sistem tekanan tinggi permanen yang berada di atas Pasifik Barat subtropis, yang secara signifikan memengaruhi fluks kelembapan atmosfer dan monsun musim panas di atas Cina Selatan (Xiao et al. 2021 ). Di sini kami memeriksa titik baratnya, luasnya, intensitasnya, dan lokasi nilai maksimumnya dalam kaitannya dengan kejadian TCER. Indeks area ( wpsh_area ) didefinisikan sebagai area bulat yang dibatasi oleh garis 5880-gpm pada 500 hPa (dalam rentang lintang 10° N–60° N dan rentang bujur 110° E–180°), dan indeks intensitas ( wpsh_intensity ) dihitung sebagai perbedaan kumulatif antara tinggi geopotensial dan 5870 gpm dikalikan dengan area titik grid di wilayah yang sama. Titik punggungan barat ( wpsh_westpoint ) adalah garis bujur paling barat dalam wilayah 10° LU–60° LU dan 90° BT–180° yang dibatasi oleh garis 5880-gpm, dan titik maksimum ( wpsh_maxpoint ) mewakili nilai tertinggi dalam garis ini. Variabel atmosfer lain yang dipertimbangkan termasuk indeks musim panas Laut Cina Selatan ( u_SCSSM ) dan indeks musim panas Asia Timur ( u_EASM ). u_EASM dihitung sebagai perbedaan rata-rata angin zonal antara (5° N–15° N, 90° E–130° E) dan (22.5° N–32.5° N, 110° E–140° E) pada 850 hPa, dan u_SCSSM adalah rata-rata angin zonal 850 hPa di atas (10° N–20° N, 110° E–120° E) di Laut Cina Selatan.
Fitur-fitur yang mendasarinya juga dipertimbangkan dalam studi ini. Data elevasi medan mentah bersumber dari data relief global grid 2-min v2 (ETOPO2v2) yang ditawarkan oleh Pusat Data Geofisika Nasional AS (NGDC) dari Badan Kelautan dan Atmosfer Nasional (NOAA), dengan resolusi 2 menit (Pusat Data Geofisika Nasional 2006 ). Untuk setiap stasiun, rata-rata ( mean_elevation ), maksimum ( max_elevation ), minimum ( min_elevation ), dan deviasi standar ( std_elevation ) dari elevasi diperkirakan. Selain itu, rentang ( range_elevation ), kemiringan ( slope_elevation ), dan aspek ( aspect_elevation ) dari elevasi dihitung. Rentang ( range_elevation ) didefinisikan sebagai perbedaan antara elevasi tertinggi dan terendah dalam setiap kotak. Kemiringan ( slope_elevation ) didefinisikan sebagai kecuraman rata-rata dalam setiap kotak, dan aspek ( spect_elevation ) mewakili arah lereng yang diukur searah jarum jam dari 0° (utara tepat).
Lebih jauh lagi, karakteristik lintasan TC merupakan faktor penting yang memengaruhi jumlah presipitasi dan lokasi TC tunggal. Menurut pedoman prakiraan operasional di Cina Selatan (Luo et al. 2018 ), lintasan TC ini dapat dibagi menjadi tiga jenis berbeda: lintasan barat laut, barat, dan timur (masing-masing disebut sebagai NWTC, WTC, dan ETC, dan digambarkan dalam warna biru, hitam, dan merah pada Gambar 1b ). Dalam studi ini, klasifikasi ini digunakan sebagai prediktor masukan (tracktype) untuk model ML, dengan NWTC, WTC, dan ETC dikodekan sebagai 0, 1, dan 2, masing-masing. Faktor lain yang dipertimbangkan termasuk lintang rata-rata ( track_lat ) dan bujur ( track_lon ), dan kecepatan angin maksimum ( wind_max ) dari TC. Jarak yang harus dilacak ( Distance to Track ), didefinisikan sebagai jarak bola terdekat (dalam kilometer) antara setiap stasiun dan lintasan TC, kecepatan U maju ( movespeed_u ), kecepatan V maju ( movespeed_v ), kecepatan maju ( movespeed ), dan sudut kecepatan maju ( movespeed_direction ) dari gerakan badai juga didefinisikan.
Variabel-variabel ini, bersama dengan variabel spasial, temporal, dan topografi (dirangkum dalam Tabel 1 ), membentuk matriks prediksi berdimensi tinggi yang terkait dengan karakteristik TCER. Perlu disebutkan bahwa kami mempertimbangkan perbedaan faktor-faktor ini sebelum dan selama terjadinya peristiwa TCER, seperti yang ditunjukkan pada kolom “waktu” pada Tabel 1. Misalnya, wpsh_westpoint(0d)-(−1d) merepresentasikan perbedaan indeks wpsh_westpoint antara hari kejadian dan 1 hari sebelum kejadiannya, dan 850hPa_qu(0d)-(−2d) merepresentasikan perbedaan fluks uap air horizontal 850 hPa antara hari kejadian dan 1 hari sebelum kejadiannya (Tabel 1 ). Secara total, 212 variabel dalam matriks prediktor digunakan sebagai input model ML awal, dan reduksi dimensionalitas dilakukan seperti yang dijelaskan dalam Bagian 2.2 .
| Nomor | Variabel | Singkatan | Tingkatan | Waktu |
|---|---|---|---|---|
| 1 | Lintang stasiun | Bahasa Inggris | — | — |
| 2 | Bujur stasiun | Panjang | — | — |
| 3 | Jarak yang harus dilacak | Jarak yang Dilacak | — | — |
| 4 | Ketinggian rata-rata | rata-rata_ketinggian | — | — |
| 5 | Ketinggian maksimum | elevasi_maksimum | — | — |
| 6 | Ketinggian minimum | elevasi_min | — | — |
| 7 | Simpangan baku | std_elevasi | — | — |
| 8 | Rentang elevasi | rentang_ketinggian | — | — |
| 9 | Kemiringan elevasi | kemiringan_elevasi | — | — |
| 10 | Aspek elevasi | aspek_elevasi | — | — |
| 11 | Jenis trek | jenis lintasan | — | — |
| 12 | Lacak garis lintang | jalur_lat | — | — |
| 13 | Lacak garis bujur | jalur_lon | — | — |
| 14 | Sektor V VWS | vw_v_di_kota | — | (0d); (−1d); (−2d); (0d)-(−1d); (0d)-(−2d) |
| 15 | Sektor U dari VWS | vws_kamu | — | Sama |
| 16 | Pesawat VW | mobil VW | — | Sama |
| 17 | Arah VWS | vws_arah | — | Sama |
| 18 | Sektor U kecepatan bergerak | kecepatan_gerak_u | — | Sama |
| 19 | Sektor V kecepatan bergerak | kecepatan_gerak_v | — | Sama |
| 20 | Kecepatan bergerak | kecepatan gerak | — | Sama |
| 21 | Arah kecepatan bergerak | arah_kecepatan_gerak | — | Sama |
| 22 | Kecepatan angin maksimum pusat TC | angin_maks | — | Sama |
| 23 | Titik barat WPSH | wpsh_titik_barat | — | Sama |
| 24 | Indeks wilayah WPSH | daerah wpsh | — | Sama |
| 25 | Indeks intensitas WPSH | intensitas_wpsh | — | Sama |
| 26 | Titik maksimum WPSH | wpsh_titik_maksimum | — | Sama |
| 27 | indeks EASM | u_EASM | — | Sama |
| 28 | indeks SCSSM | u_SCSSM | — | Sama |
| 29 | Kelembaban spesifik | Q | Tekanan 925hPa, 850hPa, 700hPa | Sama |
| 30 | Sektor U uap air | apa | Tekanan 925hPa; 850hPa | Sama |
| 31 | Sektor V uap air | pertanyaan | Tekanan 925hPa; 850hPa | Sama |
| 32 | Uap air | qwspd | Tekanan 925hPa; 850hPa | Sama |
| 33 | Divergensi uap air | qdiv | Tekanan 925hPa; 850hPa | Sama |
| 34 | Angin V | kita | Tekanan 925hPa, 850hPa, 200hPa | Sama |
| 35 | Vortisitas angin | sebelum | Tekanan 925hPa; 850hPa | Sama |
| 36 | Suhu potensial setara | tetae (bahasa Inggris: thetae) adalah bahasa yang digunakan untuk menggambarkan kehidupan manusia. | Tekanan 850hPa; 500hPa | Sama |
| 37 | Gradien suhu potensial setara | delta_thetae | — | Sama |
| 38 | Akhir | aku | Tekanan 700hPa; 500hPa | Sama |
| 39 | Adveksi vortisitas angin | iklan_vor | Tekanan 500hPa | Sama |
| 40 | Ketinggian geopotensial | tinggi | Tekanan 500hPa dan 200hPa | Sama |
| 41 | Divergensi angin | membagi | Tekanan 200hPa | Sama |
| 42 | Angin U | kamu | Tekanan 200hPa | Sama |
2.2 Pengembangan ML
Seperti yang disebutkan sebelumnya, tujuan dari penelitian kami adalah untuk mengembangkan model ML klasifikasi biner untuk mengidentifikasi kejadian TCER dan model berbasis regresi untuk memprediksi curah hujan harian. Model klasifikasi biner menggunakan pembelajaran terbimbing untuk memetakan variabel fisik multiskala ke target prakiraan dua kategori (di mana kejadian TCER diberi label 1 dan kejadian non-TCER diberi label 0).
Untuk menyelidiki variabel fisik multiskala yang berkontribusi pada kejadian TCER, dan untuk memodelkan hubungan rumit dan non-linier antara variabel fisik dan kejadian TCER pada GX, serta untuk membangun sistem prediksi yang tangguh, tiga model pembelajaran terbimbing dengan kompleksitas yang meningkat diuji pada matriks data yang dikumpulkan. Model-model ini adalah RF, Boost adaptif yang diterapkan pada pohon keputusan (AdaBoost), dan boosting gradien ekstrem yang diterapkan pada pohon keputusan (XGBoost), yang banyak digunakan dalam tugas regresi dan klasifikasi dengan kinerja prediktif yang tinggi.
RF, suatu himpunan pohon keputusan, mengurangi varians dan memitigasi overfitting dengan memperkenalkan keacakan dan memiliki kapabilitas untuk memberi peringkat prediktor (Breiman 2001 ; Biau 2012 ; Boulesteix et al. 2012 ). AdaBoost adalah algoritma boosting adaptif yang secara berurutan melatih serangkaian pohon keputusan univariat (Ying et al. 2012 ) dan secara progresif meningkatkan kinerja model dengan menyesuaikan bobot sampel (Coughlan et al. 2021 ). XGBoost adalah versi yang disempurnakan dari algoritma berdasarkan pohon keputusan boosting gradien, yang menawarkan optimasi, regularisasi, dan komputasi terdistribusi turunan orde kedua untuk efisiensi dan akurasi yang lebih tinggi tetapi memerlukan penyetelan hiperparameter yang cermat (Chen dan Guestrin 2016 ). Masing-masing dari ketiga algoritma ini memiliki kelebihan dan kekurangannya sendiri. Dalam studi ini, kinerja model-model ini dievaluasi secara komprehensif untuk memilih yang optimal. Proses pembangunan model melibatkan tiga langkah: praproses data, pemilihan fitur, dan penyetelan hiperparameter.
2.2.1 Praproses Data
Mengingat hanya sebagian kecil data yang berisi nilai yang hilang, penelitian ini langsung menghapus catatan tersebut dan menormalkan data sebelum pembentukan model. Kumpulan data dikategorikan ke dalam dua kategori: non-TCER (diberi label 0) dan kejadian TCER (diberi label 1), dengan 80% data dialokasikan untuk pelatihan dan 20% untuk pengujian (masing-masing 20.420 dan 5.106 catatan). Semua variabel atmosfer digunakan sebagai prediktor, dan kumpulan data yang sama diterapkan di berbagai model untuk memungkinkan perbandingan kinerja.
Untuk model klasifikasi biner, kelas non-TCER memiliki ukuran sampel yang jauh lebih besar, yang mengarah ke sensitivitas rendah dalam mendeteksi kejadian TCER (Cheng et al. 2015 ). Untuk mengatasi hal ini, kami mengeksplorasi metode pemrosesan sampel yang tidak seimbang pada tingkat sampel, algoritma model, dan metodologi integrasi. Pada tingkat sampel, metode resampling seperti oversampling acak, undersampling acak (Lemaitre et al. 2017 ), Synthetic Minority Over-Sampling Technique (SMOTE), SMOTE dikombinasikan dengan undersampling (SMOTE_Undersampling), SMOTE dikombinasikan dengan Edited Nearest Neighbor (SMOTEENN), SMOTE dikombinasikan dengan tautan Tomek (SMOTETomek), dan pendekatan pengambilan sampel Adaptive Synthetic (ADASYN), dll., digunakan. Pada tingkat algoritma model, penyesuaian bobot kelas diterapkan (Grazzini et al., 2024 ). Pada tingkat metodologi integrasi, metode EasyEnsemble digunakan. Metode ini tidak digunakan dalam kumpulan data uji untuk menghindari prediksi berlebihan terhadap kejadian TCER.
2.2.2 Pemilihan Fitur
Matriks prediktor awal dengan 212 variabel mengalami masalah seperti redundansi data dan potensi overfitting. Untuk mengatasi masalah ini, proses reduksi dimensionalitas diterapkan pada matriks prediktor berdimensi tinggi untuk setiap algoritma di wilayah GX. Beberapa metode pemilihan fitur digunakan untuk mengidentifikasi subset variabel penjelas yang optimal untuk mencapai prediksi terbaik. Metode-metode ini meliputi Recursive Feature Elimination with Cross-Validation (RFECV), SelectFromModel (SFM), SelectFromModel combined with LassoCV (SFM_Lasso), SelectKBest (SKB), dan SequentialFeatureSelector (SFS), yang semuanya diimplementasikan menggunakan modul sklearn dalam Python (untuk detail lebih lanjut, lihat Tabel 2 ).
| Metode | Pengenalan singkat | Elemen kunci |
|---|---|---|
| Penghapusan fitur rekursif (RFECV) | RFE memeringkat fitur dan melakukan validasi silang untuk menemukan jumlah fitur yang optimal; | fitur_maks = 20 |
| Pilih dari model (SFM) | Fitur dipilih berdasarkan ambang batas dan bobot kepentingan: fitur yang memiliki kepentingan lebih tinggi atau sama dipertahankan, dan sisanya dibuang. | ambang batas = 0,01/“3*rata-rata”/“1,5*rata-rata” |
| Pilih dari model-lasso CV (SFM_Lasso) | Metode SelectFromModel berdasarkan Paradigma L1 Penalti | hubungan sebab akibat = 5 |
| Pilih KBest (SKB) | SKB memilih K fitur dengan skor tertinggi berdasarkan fungsi penilaian. | k = 20 |
| Pemilih fitur berurutan (SFS) | SFS dimulai dengan set kosong, menambahkan satu fitur per putaran, melatih model, mempertahankan fitur yang ditambahkan jika skor evaluasi meningkat, dan berhenti ketika jumlah fitur mencapai nilai yang ditetapkan oleh parameter n_features_to_select | n_fitur_yang_dipilih = 20 |
| Algoritma genetik (GA) | GA menentukan set fitur optimal melalui proses seperti seleksi alam. | fitur_min = 5, fitur_maks = 20 |
Dengan menggunakan metode-metode ini untuk memilih variabel dari data pelatihan, skor kepentingan variabel (VI) dari fitur-fitur yang dipilih diperoleh. Skor-skor ini mengevaluasi pentingnya variabel-variabel dalam memprediksi kejadian TCER berdasarkan peningkatan ketidakmurnian Gini (Zhu dan Aguilera 2021 ). Variabel-variabel yang dipilih kemudian dilatih ulang pada data uji. Algoritma genetika (GA) selanjutnya digunakan untuk lebih mengoptimalkan model, mengurangi kompleksitasnya dan risiko overfitting yang terkait (Chen et al. 2020 ). Dalam model akhir, metode Shapley additive explanations (SHAP) digunakan untuk meningkatkan interpretabilitas model, memvisualisasikan kontribusi setiap fitur terhadap prediksi (Lundberg et al. 2017 ).
2.2.3 Optimasi Hiperparameter
Langkah terakhir dalam proses pengembangan model adalah optimasi hiperparameter. Kami menggunakan GridSearch dan RandomSearch dari pustaka scikit-learn dalam Python untuk menguji berbagai nilai hiperparameter pada set data pelatihan. Untuk setiap model, validasi silang lima kali lipat dilakukan. GridSearch adalah metode yang menelusuri secara menyeluruh serangkaian kombinasi hiperparameter yang telah ditentukan sebelumnya untuk menentukan nilai optimal, sementara RandomSearch secara acak memilih serangkaian kombinasi dari ruang hiperparameter yang diberikan untuk evaluasi.
Dengan mempertimbangkan perbedaan hiperparameter di antara berbagai model, untuk RF, RandomSearch dan GridSearch digunakan untuk mengoptimalkan hiperparameter seperti jumlah pohon (n_estimator) dan kedalaman maksimum (max_depth). AdaBoost mengoptimalkan hiperparameter seperti jumlah pengklasifikasi lemah (n_estimator) dan laju pembelajaran (learning_rate) melalui GridSearch. XGBoost mengoptimalkan hiperparameter seperti jumlah pohon (num_round) dan laju pembelajaran (eta) menggunakan GridSearch. Nilai hiperparameter yang menghasilkan kinerja model terbaik dipilih untuk model akhir.
2.3 Evaluasi Model
Kinerja model dapat dievaluasi menggunakan berbagai metrik. Dalam konteks TCER atau peristiwa presipitasi, positif benar terjadi ketika pengklasifikasi memprediksi dengan tepat terjadinya peristiwa presipitasi. Positif salah dicatat ketika pengklasifikasi salah memperkirakan peristiwa presipitasi yang sebenarnya tidak terjadi. Negatif benar terjadi ketika pengklasifikasi mengidentifikasi dengan tepat tidak adanya peristiwa presipitasi, dan negatif salah terjadi ketika pengklasifikasi gagal memprediksi peristiwa presipitasi yang sebenarnya terjadi.
Untuk klasifikasi kejadian TCER, presisi, recall, skor F1, dan Skor Ancaman (TS) digunakan. Presisi mengukur proporsi prediksi positif benar dari kejadian TCER di antara semua prediksi positif. Recall, juga dikenal sebagai rasio probabilitas deteksi (POD), adalah rasio prediksi positif benar terhadap jumlah total pengamatan positif aktual. Skor F1 memberikan keseimbangan antara presisi dan recall, berkisar antara 0 hingga 1, di mana skor F1 yang lebih tinggi menunjukkan keseimbangan yang lebih baik antara kedua metrik tersebut. Skor TS menilai keakuratan prakiraan curah hujan ekstrem dan merupakan salah satu skor yang umum digunakan untuk mengevaluasi keakuratan curah hujan ekstrem atau tingkat prakiraan curah hujan tertentu. Ini dihitung sebagai fraksi positif benar dibagi dengan jumlah positif benar, positif salah, dan negatif salah, dengan nilai TS berkisar antara 0 hingga 1. Nilai TS yang lebih tinggi menunjukkan prakiraan yang lebih akurat.
Untuk prediksi curah hujan harian, digunakan nilai root mean square error (RMSE) dan R-squared. Selain itu, kami menerapkan metrik model klasifikasi pada tingkat curah hujan 50 mm, yang umumnya digunakan dalam prakiraan operasional.
3 Hasil
3.1 Kinerja Model dan Interpretabilitas Fisik Model Klasifikasi untuk Kejadian Peristiwa TCER
3.1.1 Pengembangan Model dan Evaluasi Kinerja
Untuk mengatasi masalah ketidakseimbangan dalam memprediksi kejadian TCER, studi ini menggunakan tiga algoritma (XGBoost, RF, AdaBoost), sembilan teknik untuk pengambilan sampel ulang data yang tidak seimbang, dan lima metode pemilihan fitur untuk mengidentifikasi kumpulan variabel yang optimal. Dengan mengintegrasikan pendekatan ini, total 202 eksperimen dirancang untuk memperkirakan kejadian (diwakili sebagai 0 atau 1) kejadian TCER. Kinerja eksperimen ini dievaluasi menggunakan Threat Score (TS), presisi, recall, dan skor F1. 20 model teratas yang dihasilkan dari eksperimen ini dirangkum dalam Tabel 3 .
| Angka | Algoritma | Pemilihan fitur | Metode resampling | Nomor fitur | Presisi | Mengingat | Bahasa Indonesia: F1 | TS |
|---|---|---|---|---|---|---|---|---|
| Nomor telepon 1* | Bahasa Inggris: XGB | SFM-1,5*rata-rata | ADASYN | 32 | 0.47 | 0.62 | 0.54 | 0.37 |
| 2 | Bahasa Inggris: XGB | SFM-1,5*rata-rata | Pengambilan sampel berlebih | 32 | 0.49 | 0.57 | 0.53 | 0.36 |
| 3 | Bahasa Inggris: XGB | Bahasa Indonesia: RFECV | Pengambilan sampel berlebih | 165 | 0.52 | 0.51 | 0.52 | 0,35 |
| 4 | Bahasa Inggris: XGB | Boruta | Pengambilan sampel berlebih | 121 | 0.5 | 0.54 | 0.52 | 0,35 |
| 5 | Bahasa Inggris: XGB | SFM-Lasso CV | ADASYN | 127 | 0.49 | 0,55 | 0.52 | 0,35 |
| 6 | Bahasa Inggris: XGB | Boruta | ADASYN | 153 | 0.49 | 0.56 | 0.52 | 0,35 |
| nomor 7 | Bahasa Inggris: XGB | SFM-0,01 | Pengambilan sampel berlebih | 25 | 0.47 | 0,59 | 0.52 | 0,35 |
| 8 | Bahasa Inggris: XGB | Boruta | SMOTET Tomek | 146 | 0.46 | 0,55 | 0.5 | 0.34 |
| 9 | Bahasa Inggris: XGB | SFM-1,5*rata-rata | Ambang | 35 | 0.56 | 0.46 | 0.51 | 0.34 |
| 10 | Bahasa Inggris: XGB | Boruta | MENGHANCURKAN | 131 | 0.49 | 0.54 | 0.51 | 0.34 |
| 11 | Bahasa Inggris: XGB | SFM-Lasso CV | MENGHANCURKAN | 127 | 0.49 | 0.54 | 0.51 | 0.34 |
| 12 | Bahasa Indonesia: Frekuensi Radio | Boruta | ADASYN | 205 | 0.47 | 0.56 | 0.51 | 0.34 |
| 13 | Bahasa Indonesia: Frekuensi Radio | Boruta | SMOTET Tomek | 205 | 0.46 | 0.56 | 0.51 | 0.34 |
| 14* | Bahasa Inggris: XGB | SFM-3*rata-rata | Pengambilan sampel berlebih | 18 | 0.46 | 0.57 | 0.51 | 0.34 |
| 15 | Bahasa Inggris: XGB | SFM-1,5*rata-rata | SMOTET Tomek | 32 | 0.43 | 0.61 | 0.51 | 0.34 |
| 16 | Bahasa Inggris: XGB | Bahasa Indonesia: RFECV | SMOTEENN | 176 | 0.37 | 0.8 | 0.51 | 0.34 |
| 17 | Bahasa Inggris: XGB | Bahasa Indonesia: RFECV | SMOTET Tomek | 191 | 0.46 | 0.53 | 0.49 | 0.33 |
| 18 | Bahasa Indonesia: Frekuensi Radio | Bahasa Indonesia: RFECV | SMOTET Tomek | 208 | 0.44 | 0,55 | 0.49 | 0.33 |
| 19 | Bahasa Indonesia: Frekuensi Radio | SFM-Lasso CV | ADASYN | 127 | 0.47 | 0.54 | 0.5 | 0.33 |
| 20 | Bahasa Indonesia: Frekuensi Radio | SFM-Lasso CV | MENGHANCURKAN | 127 | 0.46 | 0.54 | 0.5 | 0.33 |
Catatan: * di kolom Nomor mewakili model yang dibahas.
Berdasarkan peringkat indeks evaluasi algoritma, model XGBoost menunjukkan kinerja yang unggul, mengamankan 15 dari 20 posisi teratas dalam hal skor TS (Tabel 3 ). Model tersebut mencapai TS rata-rata sebesar 0,37 (±0,02), yang secara signifikan mengungguli model RF dan AdaBoost. Hasil ini menggarisbawahi ketahanan XGBoost dalam menangani tugas klasifikasi biner dengan kumpulan data yang tidak seimbang.
Mengenai metode pemilihan fitur, metode SFM secara efektif mengurangi dimensionalitas data dengan memilih prediktor penting dari kumpulan awal lebih dari 200 variabel. Ini tidak hanya memfasilitasi pembentukan model prediksi berikutnya tetapi juga menyederhanakan rumus perkiraan. Dalam hal teknik resampling, metode oversampling, seperti SMOTE, sebagian besar ditemukan di antara model peringkat teratas (Tabel 3 ). Ini terbukti khususnya untuk kumpulan data dengan ketidakseimbangan kelas yang ekstrem, kemungkinan karena kemampuannya untuk melawan bias yang timbul dari frekuensi kemunculan peristiwa TCER. Dengan meningkatkan proporsi peristiwa positif, metode ini meningkatkan pengaruh faktor-faktor utama yang terkait dengan peristiwa TCER.
Tabel 3 menunjukkan bahwa model peringkat teratas (No. 1, dengan skor TS 0,37) dibangun menggunakan 32 variabel penjelas potensial. Sebaliknya, model No. 7 (dengan 25 variabel) dan No. 14 (dengan 18 variabel), mencapai skor TS yang sebanding yaitu 0,35 dan 0,34, meskipun memiliki lebih sedikit variabel. Plot kepentingan fitur yang diperingkat untuk model No. 1, No. 7, dan No. 14 (selanjutnya disebut sebagai Model CNo. 1, CNo. 7, dan CNo. 14, masing-masing, Model CNo. 14 digambarkan dalam Gambar 2 , sementara model CNo. 1 dan CNo. 7 ditunjukkan dalam Gambar S1 dan S2 dari Informasi Pendukung daring ) mengindikasikan bahwa semua model ini menangkap penggerak fisik inti, seperti Jarak ke Jalur , track_lat, 500hPa_w(0d) , 500hPa_thetae(0d) , vws_u(−2d) , movespeed_u(0d) , dst. Variabel-variabel ini berperingkat tinggi dalam ketiga model, mencakup 41%, 61%, dan 73% dari total kepentingan fitur (Tabel 4 ), yang menunjukkan kekokohannya dalam prediksi TCER. Khususnya, Distance to Track , track_lat , dan 500hPa_w(0d) termasuk di antara empat variabel signifikan teratas dalam semua model. Selain itu, variabel-variabel ini konsisten dengan mekanisme curah hujan TC yang sudah mapan (misalnya, interaksi medan, transportasi kelembapan, pengangkatan dinamis), yang memvalidasi relevansi fisiknya di berbagai metode pemilihan fitur.
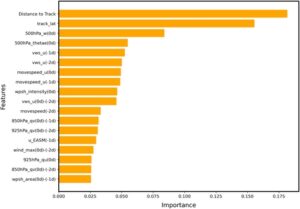
| Angka | Variabel | CNo. 1 fitur penting | CNo. 7 fitur penting | CNo. 14 fitur penting | Peran fisik |
|---|---|---|---|---|---|
| 1 | Jarak yang harus dilacak | 0.10 | 0.19 | 0.18 | Kedekatan dengan pusat TC, mempengaruhi intensitas TC |
| 2 | jalur_lat | 0,09 | 0,15 | 0.16 | Modulasi aliran masuk kelembapan dan interaksi medan |
| 3 | 500hPa_w(0d) | 0.11 | 0,06 | 0,08 | Meningkatkan gerakan ke atas dan aktivitas konvektif |
| 4 | 500hPa_thetae(0d) | 0,05 | 0,03 | 0,05 | Prediktor ketidakstabilan |
| 5 | vws_u(−2d) | 0,05 | 0,05 | 0,05 | Mempengaruhi organisasi badai dan distribusi curah hujan |
| 6 | kecepatan_gerak_u(0d) | 0,04 | 0,09 | 0,05 | Kecepatan terjemahan TC secara real-time |
| 7 | kecepatan_gerak_u(−1d) | 0,02 | 0,03 | 0,05 | Kecepatan penerjemahan TC sebelum waktunya |
| 8 | wpsh_intensitas(0d) | 0,02 | 0,03 | 0,05 | Prediktor skala besar waktu nyata |
| 9 | 925hPa_qv(0d)-(−2d) | 0,01 | 0,01 | 0,03 | Sinyal prekursor skala besar |
| 10 | angin_maks(0d)-(−2d) | 0,02 | 0,03 | 0,03 | Menangkap perubahan intensitas 48 jam |
| Total | — | 0.41 | 0.61 | 0.73 |
Model CNo. 7 menyertakan semua variabel Model CNo. 14, dan faktor termal-dinamis tambahannya (misalnya, 850hPa_q(0d) , movespeed_direction(0d)-(−2d) dan u_SCSSM(0d )) memberikan kontribusi marjinal terhadap prediksi presipitasi (ΔTS = 0,01). Model CNo. 14, dengan set fitur yang lebih ringkas, mempertahankan variabel yang terkait erat dengan kejadian TCER, memenuhi persyaratan operasional waktu nyata dan menjadi kandidat yang layak untuk model optimal. Sebaliknya, Model CNo. 1 memprioritaskan banyak prediktor termodinamika dan skala besar, yang menunjukkan redundansi. Untuk mengoptimalkan Model CNo. 1, algoritma genetika (GA) dengan validasi silang lima kali lipat diterapkan padanya. Model optimal yang dipilih oleh GA (selanjutnya disebut Model CNo. 1-GA) mempertahankan 15 prediktor tetapi hanya menunjukkan peningkatan marjinal (TS = 0,35 dibandingkan dengan TS Model CNo. 1 = 0,36), yang menunjukkan bahwa GA merupakan metode pemilihan fitur yang efektif untuk mengurangi jumlah prediktor.
Mengingat bahwa jumlah set fitur optimal yang disaring oleh GA berbeda dari jumlah fitur Model CNo. 14 hanya tiga, dan bertujuan untuk meningkatkan keandalan model dan meminimalkan dampak dimensionalitas dan noise, studi ini melakukan optimasi hiperparameter lebih lanjut. Performa prediksi Model CNo. 1, Model CNo. 1-GA yang dioptimalkan, dan Model CNo. 14 dievaluasi dan dibandingkan. Penyetelan hiperparameter berikutnya (Tabel 5 ) menunjukkan bahwa Model CNo. 14 (dengan 18 prediktor) adalah yang paling optimal, mencapai skor TS 0,41 dan nilai F1 0,58. Performa ini melampaui Model CNo. 1 (TS = 0,36, F1 = 0,53) dan Model CNo. 1-GA (TS = 0,35, F1 = 0,52). Meskipun terjadi penurunan sedang dalam mengingat (0,59 dibandingkan dengan 0,6–0,61), keseimbangan seimbang antara presisi dan mengingat (presisi = 0,58) membenarkan penerapan Model CNo. 14 sebagai model akhir untuk analisis lebih lanjut.
| Angka | Algoritma | Pemilihan fitur | Metode resampling | Nomor fitur | Presisi | Mengingat | Bahasa Indonesia: F1 | TS |
|---|---|---|---|---|---|---|---|---|
| Nomor C 1 | Model nomor 1 | SFM-1,5*rata-rata | ADASYN | 32 | 0.46 | 0.62 | 0.53 | 0.36 |
| Nomor C14* | Model nomor 14 | SFM-3*rata-rata | Pengambilan sampel berlebih | 18 | 0,58 | 0,59 | 0,58 | 0.41 |
| Nomor C 1-GA | Model nomor 1-GA | SFM-1,5*rata-rata | ADASYN | 15 | 0.46 | 0.6 | 0.52 | 0,35 |
Catatan: * di kolom Angka mewakili model optimal.
Kesimpulannya, kerangka kerja penguat gradien XGBoost secara efektif mengelola interaksi nonlinier dalam kumpulan data yang tidak seimbang. Penggunaan metode oversampling yang meluas menyoroti perlunya menggunakan strategi resampling yang disesuaikan dalam memprediksi kejadian langka. Kombinasi metode SFM dan GA mengurangi jumlah prediktor hingga 70% tanpa menurunkan kinerja model secara signifikan. Model CNo. 14 mengungguli model lain, mencapai skor TS sebesar 0,41. Kesederhanaannya, hanya mengandalkan 18 prediktor dibandingkan dengan model operasional yang biasanya menggunakan lebih dari 50 variabel, merangkum mekanisme termodinamika-dinamis utama TCER sambil menghindari gangguan dari fitur yang berlebihan, yang menyiratkan adanya trade-off antara interpretabilitas dan kelengkapan.
3.1.2 Pentingnya Fitur dan Interpretabilitas Fisik
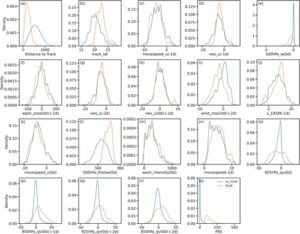
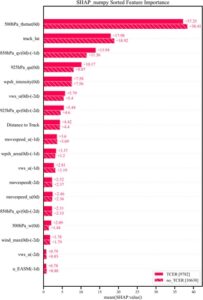
Seperti yang disebutkan sebelumnya, Model CNo. 14 menggabungkan 18 prediktor (Gambar 2 ), yang meliputi sinyal dinamis, termal, kelembapan, ketidakstabilan, dan prekursor, yang digunakan untuk memperkirakan terjadinya peristiwa TCER. Gambar 3 menyajikan fungsi kerapatan probabilitas (PDF) dari variabel-variabel ini, yang mengungkap perbedaan yang jelas dalam distribusi PDF dari variabel-variabel tertentu yang dipilih antara peristiwa TCER dan non-TCER. Variabel seperti Distance to Track , track_lat , 500hPa_w(0d) , wind_max(0d)-(−2d) , 500hPa_thetae(0d) , 850hPa_qv(0d)-(−1d) , dan 850hPa_qv(0d)-(−2d) menunjukkan perbedaan yang nyata dalam kemiringan dan kurtosis PDF-nya, yang menjadikannya representatif untuk konstruksi model. Sebaliknya, variabel seperti vws_u(−1d) , vws_u(0d)-(−2d) , dan wpsh_area(0d)-(−1d) tidak secara efektif membedakan antara dua kategori kejadian.
Fitur-fitur pada Gambar 2 diurutkan menurut kepentingannya, dengan perbandingan kuantitatif signifikansinya. Distance to Track berada di peringkat pertama, yang menunjukkan hubungan kuat antara kemunculan peristiwa TCER dan jarak dari pusat TC. Temuan ini selaras dengan hasil Zhu dan Aguilera ( 2021 ), yang memverifikasi bahwa Distance to track merupakan variabel paling krusial saat menilai variasi presipitasi TC di Meksiko Timur menggunakan teknik ML. Setelah Distance to Track adalah track_lat , 500hPa_w(0d) , dan 500hPa_thetae(0d) , sementara 925hPa_qu(0d) , 850hPa_qv(0d)-(−1d) , dan wpsh_area(0d)-(−1d) memiliki kepentingan yang relatif lebih rendah. Mengingat penelitian sebelumnya dan perkiraan operasional telah mengidentifikasi pengisian ulang fluks uap air pada 850 hPa, perubahan VWS sebelum peristiwa TCER, dan variasi suhu setara 500 hPa sebagai faktor utama dalam terjadinya peristiwa TCER, menganalisis signifikansi fitur hanya berdasarkan keluaran langsung model akhir mungkin saja berat sebelah.
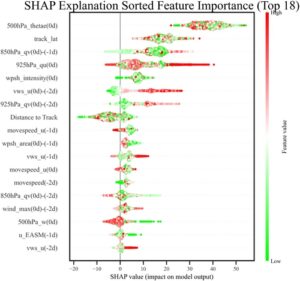
Dengan memperhitungkan ketidakseimbangan sampel, evaluasi lebih lanjut terhadap kontribusi fitur sangatlah penting. Studi ini menggunakan metode SHAP untuk meningkatkan interpretabilitas model ML yang sangat transparan. Meskipun urutan nilai SHAP untuk fitur berbeda antara kejadian TCER dan non-TCER, lima variabel paling berpengaruh tetap konsisten: Jarak ke Jalur , 850hPa_qv(0d)-(−1d) , 925hPa_qu(0d) , vws_u(−1d) , dan 500hPa_thetae(0d) (Gambar 4 ), yang sejalan dengan pertimbangan operasional praktis.
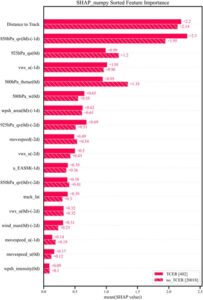
Jarak ke Jalur dan 850hPa_qv(0d)-(−1d) adalah dua variabel yang paling menonjol (Gambar 4 ). Dalam hal besaran absolut, dampak Jarak ke Jalur pada kejadian TCER sebanding dengan kejadian non-TCER. Gambar 5 juga memberikan nilai SHAP positif dan negatif dari setiap fitur, yang masing-masing mewakili peningkatan probabilitas dan penekanan kejadian presipitasi ekstrem. Nilai SHAP dari Jarak ke Jalur adalah negatif terlepas dari kedekatannya (Gambar 5 ), yang menunjukkan kontribusi negatif yang konsisten terhadap prediksi model dan menekan probabilitas perkiraan kejadian TCER. Ini konsisten dengan asimetri presipitasi yang disebabkan oleh TC, yang mungkin disebabkan oleh efek gabungan dari jalur TC, pengangkatan topografi, dan gangguan sirkulasi multiskala (misalnya, Cai et al. 2023 ; Dong et al. 2010 ; Jiang et al. 2018 ; Qiu et al. 2019 ). Kontribusi independen Jarak ke Jalur melemah karena korelasinya yang tinggi dengan fitur-fitur lain (misalnya, kelembapan tingkat rendah, dan kecepatan vertikal). Misalnya, dalam rentang jarak tertentu, pegunungan pesisir mungkin telah menghalangi curah hujan lebat di area inti TC, yang menyebabkan perbedaan signifikan di wilayah curah hujan aktual. Di luar rentang ini, peningkatan jarak mengurangi kemungkinan curah hujan karena pengaruh aliran penurunan, yang mengarah pada konvergensi nilai-nilai SHAP. 850hPa_qv(0d)-(−1d) , yang mewakili perubahan 24 jam dalam transportasi uap air meridional tingkat rendah, memiliki nilai SHAP absolut sebesar 2,3 dan 1,95 untuk kejadian TCER dan non-TCER, masing-masing (Gambar 4 ), yang menunjukkan bahwa ia memiliki dampak yang lebih besar pada kejadian TCER daripada pada kejadian non-TCER (Gambar 5 ). Itu berkorelasi positif dengan TCER, karena nilai fitur positif sesuai dengan nilai SHAP positif. Peningkatan signifikan dalam transportasi uap air meridional tingkat rendah (misalnya, peningkatan aliran masuk hangat dan lembab) menyediakan kondisi air yang diperlukan untuk konveksi, dan nilai SHAP positif menunjukkan bahwa model tersebut mengidentifikasi akumulasi uap air sebagai prekursor utama presipitasi ekstrem.
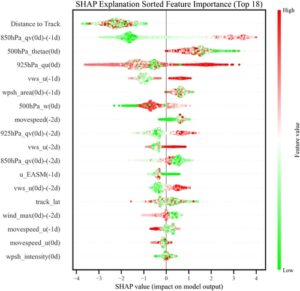
Tiga variabel lain yang berkorelasi signifikan dengan TCER adalah 925hPa_qu(0d) , vws_u(−1d) , dan 500hPa_thetae(0d) . 925hPa_qu(0d) berkorelasi positif dengan TCER dan memiliki dampak lebih besar pada kejadian non-TCER daripada pada kejadian TCER (Gambar 4 ). Kontribusinya terhadap nilai SHAP tetap relatif stabil pada nilai fitur rendah tetapi bervariasi secara substansial pada nilai yang lebih tinggi (Gambar 5 ). Ini masuk akal karena fluks uap air horizontal 925-hPa yang rendah menyiratkan lebih sedikit uap air, sehingga memiliki sedikit dampak pada kejadian TCER, sementara fluks yang lebih tinggi kondusif untuk peningkatan presipitasi, menunjukkan bahwa sumber uap air yang berbeda dapat memengaruhi fluks uap air latitudinal. Mengenai vws_u(−1d) , ia memiliki nilai SHAP absolut sebesar 1,01 dan 0,96 untuk kejadian TCER dan non-TCER, masing-masing (Gambar 4 ), yang menunjukkan bahwa ia memiliki dampak yang sebanding pada kejadian non-TCER dan TCER. Nilai tinggi vws_u(−1d) berkorespondensi dengan nilai SHAP positif, dan nilai rendah berkorespondensi dengan nilai SHAP negatif (Gambar 5 ), yang menunjukkan bahwa peningkatan VWS horizontal pada hari sebelum presipitasi dalam model mendukung peningkatan presipitasi. 500hPa_thetae(0d) , yang mewakili kondisi termal, memiliki nilai SHAP absolut sebesar 0,95 dan 1,35 untuk kejadian TCER dan non-TCER, masing-masing (Gambar 4 ), yang menunjukkan bahwa ia memiliki dampak yang lebih besar pada TCER daripada pada kejadian non-TCER. Hal ini sesuai dengan nilai SHAP positif, yang berarti bahwa suhu setara 500 hPa pada hari terjadinya TCER dalam model berkontribusi positif terhadap presipitasi (Gambar 5 ). Secara fisik, hal ini masuk akal karena suhu potensial setara troposfer tengah yang tinggi mencerminkan akumulasi energi panas lembap, dan nilai SHAP positif menunjukkan bahwa model tersebut memanfaatkan ketidakstabilan atmosfer untuk memprediksi pemicu konveksi yang kuat, yang dikaitkan dengan kejadian TCER.
Variabel penting lainnya dalam model, seperti 500hPa_w(0d) , wpsh_area(0d)-(−1d) , movespeed(−2d) , dan wind_max(0d)-(−2d) , juga memiliki interpretasi yang berarti. 500hPa_w(0d) hampir berkorelasi negatif dengan nilai SHAP (Gambar 5 ), yang menunjukkan bahwa gerakan ke atas (dengan nilai fitur yang lebih kecil tetapi SHAP positif) memiliki dampak positif pada prediksi model dan model secara langsung menghubungkan fitur ini dengan kondisi dinamis curah hujan lebat. wpsh_area(0d)-(−1d) (perubahan di area NWPSH) juga memiliki dampak positif pada prediksi model (Gambar 5 ), yang berarti bahwa perluasan NWPSH ke arah barat (nilai positif) mungkin telah memblokir pergerakan TC ke utara, memaksanya untuk tetap atau bergerak ke selatan, sehingga memperpanjang durasi curah hujan lebat. Ini menunjukkan bahwa model secara tidak langsung menangkap efek pemblokiran sirkulasi melalui fitur ini. movespeed(−2d) , yang merepresentasikan kecepatan pergerakan TC 2 hari sebelumnya, juga memiliki dampak positif pada prediksi model (Gambar 5 ), yang menunjukkan bahwa kecepatan pergerakan historis yang cepat mungkin telah memperpendek waktu tinggal TC di wilayah sebelumnya dan memperpanjang durasi presipitasi lebat, meningkatkan akumulasi presipitasi. wind_max(0d)-(−2d) , yang merepresentasikan perubahan intensitas TC 48 jam, menunjukkan dampak negatif pada prediksi TCER, dengan melemahnya intensitas TC menunjukkan nilai SHAP positif (Gambar 5 ), yang menandakan bahwa melemahnya TC dengan cepat dan berkepanjangan dapat meningkatkan kemungkinan terjadinya peristiwa TCER.
Perlu dicatat bahwa model tersebut juga memvalidasi signifikansi variabel waktu-tertinggal (misalnya, “-1d”, “-2d”) dan variabel evolusi waktu (misalnya, “(0d)-(−2d)”, “(0d)-(−1d)”). Variabel-variabel ini dapat menangkap sinyal prekursor, seperti penumpukan kelembapan ( 850hPa_qv(0d)-(−1d) ), penyesuaian sirkulasi ( wpsh_area(0d)-(−1d) ), dan perubahan intensitas TC ( wind_max(0d)-(−2d) ), yang menunjukkan bahwa model tersebut secara efektif menangkap sinyal prekursor kejadian TCER (misalnya, akumulasi kelembapan, penyesuaian sirkulasi). Misalnya, 925hPa_qv(0d)-(−2d) , yang merepresentasikan perubahan 48 jam dalam pengangkutan uap air tingkat rendah, menunjukkan efek positif pada nilai SHAP, yang berarti bahwa pertumbuhan pengangkutan uap air tingkat rendah yang berkelanjutan (misalnya, peningkatan gelombang monsun) menunjukkan nilai SHAP positif, yang mengindikasikan bahwa model tersebut memperhitungkan persistensi pasokan uap air untuk prediksi TCER.
Singkatnya, Model CNo. 14 mengintegrasikan 18 prediktor yang mencakup sinyal dinamis, termal, kelembapan, ketidakstabilan, dan prekursor untuk memperkirakan terjadinya peristiwa TCER. Model ini menekankan konveksi yang didorong oleh kedekatan, akumulasi kelembapan praperistiwa, serta kondisi termodinamika, yang menciptakan keseimbangan antara interpretabilitas dan keterampilan prediktif, dan selaras dengan wawasan operasional. Model ini mengungkap kerangka interpretabilitas fisik TCER melalui fitur-fitur seperti dinamika kelembapan, gerakan vertikal, dan pemblokiran sirkulasi. Nilai SHAP menjelaskan mekanisme yang didorong oleh fitur dari model prediksi TCER, yang mengonfirmasi kemampuannya untuk mengidentifikasi faktor-faktor meteorologi utama secara wajar, seperti akumulasi kelembapan tingkat rendah, kondisi dinamika vertikal, dan aktivitas subtropis yang tinggi.
3.2 Kinerja Model, Evaluasi dan Studi Kasus Model Regresi TCER
3.2.1 Pengembangan Model dan Evaluasi Kinerja
Pada bagian sebelumnya, fokusnya adalah menganalisis model yang dirancang untuk memprediksi terjadinya peristiwa TCER. Pada bagian ini, besarnya TCER diperiksa menggunakan algoritme yang sama (RF, XGBoost, dan AdaBoost) untuk wilayah yang sama—GX. Karena set fitur yang diperlukan untuk memprediksi presipitasi dalam model regresi dapat bervariasi dari yang diperoleh melalui klasifikasi biner, studi ini bertujuan untuk mengembangkan model prediktif yang lebih akurat. Untuk mencapai tujuan ini, studi ini menggunakan tiga metode pemilihan fitur: RFECV, SFM, dan SKB, bersama dengan dua kelompok fitur. Kedua kelompok fitur ini berasal dari model klasifikasi berkinerja tinggi sebelumnya, khususnya model CNo. 14 (model terbaik) dan CNo. 1-GS. Selanjutnya, metode pemilihan fitur dan kelompok fitur ini digunakan untuk melakukan penyaringan awal, evaluasi, dan verifikasi dari ketiga algoritme di atas. Khususnya, seperti yang ditetapkan pada bagian sebelumnya, metode SFM menunjukkan kemampuan pemilihan fitur yang kuat, dengan faktor fitur utama menunjukkan variasi yang signifikan di seluruh nilai ambang batas yang berbeda. Oleh karena itu, metode SFM juga dievaluasi dan divalidasi menggunakan tiga ambang batas yang sama (untuk informasi terperinci, lihat Tabel 2 ). Secara total, 21 eksperimen dilakukan, dan hasilnya dirangkum dalam Tabel 6. Skor TS, tingkat presisi, dan tingkat ingatan dihitung berdasarkan evaluasi prediksi hujan badai dan kejadian presipitasi di atas permukaan tanah.
| Angka | Algoritma | Pemilihan fitur | Nomor fitur | Kereta | Tes | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R 2 | Presisi | Mengingat | TS | RMSE | R 2 | Presisi | Mengingat | TS | ||||
| Nomor telepon 1* | Bahasa Indonesia: Frekuensi Radio | SFS | 20 | tanggal 14.11 | 0.68 | 0,91 | 0,87 | 0.8 | pukul 14.15 | 0,65 | 0.66 | 0,65 | 0.49 |
| 2* | Bahasa Inggris: XGB | SFS | 20 | 14.43 | 0.66 | 0.9 | 0,78 | 0.72 | 14.65 | 0.63 | 0.66 | 0.62 | 0.47 |
| 3* | Bahasa Inggris: XGB | SFM-1,5*rata-rata | 35 | tanggal 15.02 | 0.63 | 0,93 | 0.82 | 0,78 | tanggal 14.22 | 0,65 | 0.67 | 0.61 | 0.47 |
| 4* | Ada | SFS | 20 | 14.8 | 0,65 | 1 | 1 | 1 | 14.34 | 0.64 | 0.69 | 0,58 | 0.46 |
| 5 | Bahasa Inggris: XGB | SFM-0,01 | 20 | 15.76 | 0.6 | 0,91 | 0,79 | 0,74 | 14.7 | 0.62 | 0.66 | 0.6 | 0.46 |
| 6 | Ada | Nomor C14 | 18 | 15.79 | 0.6 | 1 | 1 | 1 | 14.44 | 0.64 | 0.69 | 0.57 | 0,45 |
| nomor 7 | Bahasa Indonesia: Frekuensi Radio | Nomor C14 | 18 | 15.39 | 0.62 | 0,91 | 0.86 | 0,79 | 14.28 | 0.64 | 0.63 | 0.62 | 0,45 |
| 8 | Bahasa Indonesia: Frekuensi Radio | SFM-1,5*rata-rata | 20 | 15.91 | 0,59 | 0,91 | 0.84 | 0,77 | Tanggal 15.05 | 0.61 | 0.67 | 0.57 | 0,45 |
| 9 | Bahasa Inggris: XGB | Nomor C14 | 18 | 15.39 | 0.62 | 0,91 | 0,79 | 0,74 | pukul 14.45 | 0.64 | 0.64 | 0,59 | 0.44 |
| 10 | Bahasa Indonesia: Frekuensi Radio | Nomor C 1-GS | 15 | tanggal 16.05 | 0,58 | 0,91 | 0,85 | 0,78 | 15.1 | 0.6 | 0,65 | 0,58 | 0.44 |
| 11 | Ada | Nomor C 1-GS | 15 | Tanggal 16.31 | 0.57 | 1 | 1 | 1 | 15.1 | 0.6 | 0.69 | 0.54 | 0.44 |
| 12 | Bahasa Inggris: XGB | SFM-3rata-rata | 13 | 16.35 | 0.57 | 0.9 | 0,78 | 0.72 | 15.75 | 0.57 | 0.63 | 0,58 | 0.44 |
| 13 | Bahasa Inggris: XGB | Nomor C 1-GS | 15 | 16.29 | 0.57 | 0,89 | 0,78 | 0.71 | 14.97 | 0.61 | 0.61 | 0.57 | 0.42 |
| 14 | Bahasa Indonesia: Frekuensi Radio | SKB | 20 | tanggal 17.01 | 0.53 | 0.9 | 0.83 | 0.76 | 15.98 | 0.56 | 0.62 | 0,55 | 0.41 |
| 15 | Ada | SFM-1,5rata-rata | 34 | 15.92 | 0,59 | 1 | 1 | 1 | 14.98 | 0.61 | 0.71 | 0.48 | 0.41 |
| 16 | Ada | SFM-0,01 | 22 | tanggal 16.02 | 0,59 | 1 | 1 | 1 | 14.8 | 0.62 | 0.7 | 0.5 | 0.41 |
| 17 | Bahasa Inggris: XGB | SKB | 20 | 17.68 | 0.49 | 0,95 | 0,78 | 0,75 | 16.39 | 0.53 | 0,59 | 0,55 | 0.4 |
| 18 | Ada | SFM-3*rata-rata | 16 | pukul 16.15 | 0,58 | 1 | 1 | 1 | 14.98 | 0.61 | 0.7 | 0.48 | 0.4 |
| 19 | Bahasa Indonesia: Frekuensi Radio | SFM-0,01 | 10 | 16.82 | 0.54 | 0.9 | 0.83 | 0,75 | 15.75 | 0.57 | 0.62 | 0.52 | 0.4 |
| 20 | Bahasa Indonesia: Frekuensi Radio | SFM-3*rata-rata | 8 | 17.47 | 0.51 | 0,89 | 0.81 | 0,74 | 16.48 | 0.53 | 0.6 | 0.48 | 0.36 |
| 21 | Ada | SKB | 20 | 17.33 | 0.52 | 1 | 1 | 1 | tanggal 16.18 | 0.54 | 0.67 | 0.43 | 0,35 |
Catatan: * di kolom Nomor mewakili model yang dibahas
Menurut Tabel 6 , di antara metode pemilihan fitur, SFS menunjukkan kinerja yang relatif lebih unggul dalam memprediksi presipitasi ketika diterapkan dengan model regresi. Skor TS dari set uji untuk algoritma RF, XGBoost, dan AdaBoost masing-masing adalah 0,49, 0,47, dan 0,46, yang menempati peringkat pertama, kedua, dan keempat dalam hal peringkat skor TS. Hasil ini menunjukkan kemampuan SFS untuk secara efektif menyaring set fitur berkinerja tinggi dan secara akurat memprediksi presipitasi di stasiun yang mengalami hujan badai atau kejadian presipitasi di atas permukaan, yang memposisikannya sebagai kandidat yang layak untuk tahap pra-pemilihan.
Sementara itu, model No. 1 menunjukkan RMSE terendah sebesar 14,15, diikuti oleh model No. 3 dengan RMSE sebesar 14,22. Model No. 7, yang ditetapkan melalui regresi RF menggunakan kumpulan data fitur yang berasal dari metode klasifikasi biner optimal (Model CNo. 14), memiliki RMSE yang relatif rendah sebesar 14,28. Ketiga model ini menunjukkan kapasitas untuk memprediksi nilai presipitasi secara efektif dan mempertahankan tingkat akurasi prediksi tertentu, sehingga dipertimbangkan untuk dimasukkan dalam kumpulan model yang dapat dipilih. Namun, model No. 3 memilih sejumlah besar set fitur, dengan perbedaan yang dapat diabaikan dalam skor TS dan RMSE dibandingkan dengan empat model pra-pilih lainnya. Selain itu, model No. 4, meskipun menggunakan metode pemilihan fitur yang sama dengan model No. 1 dan No. 2, memiliki tingkat ingatan yang relatif rendah untuk hujan badai dan kejadian presipitasi di atas permukaan, yang menunjukkan kinerja prediksi yang buruk. Akibatnya, model No. 3 dan No. 4 dianggap dikecualikan dari set model yang dapat dipilih.
Akibatnya, studi ini menganggap model No. 1, No. 2, dan No. 7 sebagai model yang dipilih sebelumnya dan memprosesnya lebih lanjut menggunakan teknik penyetelan hiperparameter. Hasil akhir ditunjukkan pada Tabel 7. Ditemukan bahwa setelah penyetelan hiperparameter, set uji Model No. 1 mencapai skor TS 0,5 dan RMSE 13,98. Nilai-nilai ini masing-masing 0,01 lebih tinggi dan 0,4 lebih rendah, dibandingkan dengan model klasifikasi optimal (yaitu, Model No. 7-RF) yang menggunakan algoritma yang sama. Model No. 2, yang berbagi metode pemilihan fitur yang sama dengan Model No. 1, memiliki skor TS yang identik tetapi menunjukkan pengurangan 0,31 dalam RMSE dan menunjukkan kinerja yang lebih baik. Meskipun Model No. 7-XGB memiliki skor TS 0,01 lebih rendah daripada model No. 1 dan No. 2 dan tingkat penarikannya menurun sebesar 0,01, RMSE-nya adalah yang terendah di antara keduanya. Temuan ini memvalidasi bahwa Model No. 7-XGB, yang dibangun dengan rangkaian variabel fitur yang sama dengan model klasifikasi optimal di Bagian 3.1 , memiliki kemampuan peramalan yang sangat baik untuk TCER. Demi kemudahan dalam aplikasi praktis selanjutnya, penelitian ini menetapkannya sebagai model regresi optimal untuk analisis mendalam.
| Angka | Algoritma | Pemilihan fitur | Nomor fitur | Kereta | Tes | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R 2 | Presisi | Mengingat | TS | RMSE | R 2 | Presisi | Mengingat | TS | ||||
| Nomor 1 | Bahasa Indonesia: Frekuensi Radio | SFS-20 | 20 | 8.93 | 0,87 | 0.84 | 0,78 | 0.68 | 13.98 | 0.66 | 0.68 | 0,65 | 0.5 |
| Nomor 2 | Bahasa Inggris: XGB | SFS-20 | 20 | 2.61 | 0,99 | 0,97 | 0,94 | 0,91 | 13.67 | 0.67 | 0.68 | 0,65 | 0.5 |
| Nomor 7- RF | Bahasa Indonesia: Frekuensi Radio | SFM-3 berarti | 18 | 0,05 | 1 | 1 | 1 | 1 | 13.58 | 0.68 | 0.68 | 0,65 | 0.49 |
| Tidak. 7-XGB* | Bahasa Inggris: XGB | SFM-3 berarti | 18 | 2.08 | 0,99 | 0,98 | 0,95 | 0,94 | 13.57 | 0.68 | 0.68 | 0.64 | 0.49 |
Catatan: * di kolom Angka mewakili model optimal.
Grafik ringkasan SHAP menunjukkan bahwa peringkat nilai SHAP fitur untuk kejadian TCER dan non-TCER sebagian besar identik. Lima fitur paling signifikan adalah 500hPa_thetae(0d) , track_lat , 850hPa_qv(0d)-(−1d) , 925hPa_qu(0d) , dan wpsh_intensity(0d) (Gambar 6 dan 7 ), yang berbeda dari model klasifikasi. Perbedaan ini menyiratkan bahwa fitur utama untuk memprediksi kemunculan TCER dan besarnya TCER berbeda, sehingga memerlukan pemeriksaan kontribusi fitur di berbagai model. Analisis mengungkapkan bahwa lima faktor dengan bobot kontribusi substansial (Gambar 7 ) umumnya sesuai dengan nilai SHAP positif, yang menunjukkan bahwa masing-masing faktor ini memberikan kontribusi positif terhadap prediksi TCER di setiap stasiun.
Sebagai kesimpulan, model XGBoost menunjukkan efektivitas yang lebih unggul dalam memprediksi presipitasi TC dibandingkan dengan model lainnya. Dengan rasio RMSE sebesar 13,57 dalam set pengujian dan skor TS sebesar 0,49 untuk presipitasi di atas level hujan badai, Model No. 7-XGB dapat berfungsi sebagai model prediksi operasional untuk presipitasi TC di GX.
3.2.2 Perhitungan Mundur Historis Perkiraan Kasus Topan
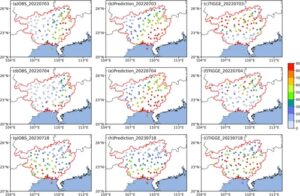
Untuk menilai lebih jauh penerapan praktis model tersebut, dua topan, yaitu “Chaba” (202203) dan “Doksuri” (202305), yang memberikan dampak signifikan pada wilayah GX selama periode 2022–2023, dipilih untuk pengujian dan penilaian. Lintasan mereka digambarkan dalam Gambar 8. Melalui verifikasi dengan data aktual, “Chaba” (202203) menghasilkan skor TS sebesar 0,26 dan tingkat ingatan yang relatif tinggi sebesar 0,91 (Tabel 8 ). Namun, RMSE-nya mencapai 30,67 mm, yang mengakibatkan perkiraan yang terlalu tinggi terhadap jumlah curah hujan. Meskipun demikian, ia masih secara signifikan mengungguli data prediksi TIGGE, yang memiliki skor TS sebesar 0,10. Dari peta distribusi presipitasi untuk 3 dan 4 Juli 2022 (Gambar 8a–f ) selama kejadian TCER pada tanggal tersebut, model tersebut mampu menangkap secara akurat besarnya presipitasi di bagian timur GX, khususnya di sekitar pusat presipitasi pesisir. Namun, model tersebut melebih-lebihkan presipitasi di bagian tenggara GX dan di sepanjang wilayah pesisir. Perbedaan ini dapat dikaitkan dengan penekanan model pada variabel seperti Distance to track , movspeed(−2d) , wind_max(0d)-(−2d) , dan vws_u(−2d) , yang semuanya terkait erat dengan jarak antara stasiun dan pusat TC. Ketika TC bergerak ke daratan dan mengubah arah, perubahan cepat dalam sirkulasi dapat menyebabkan model melebih-lebihkan presipitasi di dekat TC. Hal ini menjelaskan skor TS yang relatif tinggi (0,47 dan 0,18 pada tanggal 3 dan 4 Juli 2022, masing-masing) meskipun terdapat deviasi RMSE yang besar (masing-masing 28,1 mm dan 49,8 mm). Sebaliknya, hasil TIGGE untuk 2 hari ini memiliki skor TS sebesar 0,19 dan 0, dan gagal mengidentifikasi lokasi pusat curah hujan secara akurat, dan menunjukkan curah hujan yang sangat berlebihan di bagian barat laut GX (Gambar 8c,f ).
| Angka | Algoritma | Kasus | RMSE | R 2 | Presisi | Mengingat | TS | TIGGE-TS |
|---|---|---|---|---|---|---|---|---|
| 1 | Bahasa Inggris: XGB | Bahasa Chaba | 30.67 | 0.67 | 0.27 | 0,91 | 0.26 | 0.10 |
| 2 | Bahasa Inggris: XGB | Doksur | 22.46 | 0.39 | 0,35 | 0.44 | 0.24 | 0.18 |
| 3 | Bahasa Inggris: XGB | Total | 25.58 | 0,01 | 0.3 | 0.56 | 0.24 | 0.13 |
Untuk “Doksuri” (202305), skor TS untuk presipitasi yang melebihi level hujan badai adalah 0,24, dengan tingkat ingatan 0,56. Pada hari dengan presipitasi maksimum (18 Juli 2023) (Gambar 8g–i ), model tersebut secara efektif menangkap area dengan presipitasi tinggi di sepanjang pantai dan wilayah dengan presipitasi tinggi di bagian barat GX, yang menunjukkan kinerja prediktif yang relatif baik. Model tersebut mencapai skor TS tinggi sebesar 0,41 dan deviasi RMSE sedang sebesar 29,6 mm (Tabel 8 ), mengungguli prediksi TIGGE, yang memiliki skor TS sebesar 0,25 dan deviasi RMSE yang jauh lebih tinggi sebesar 50,5 mm.
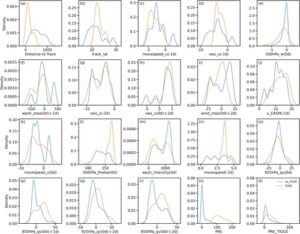
Bahasa Indonesia: Saat memeriksa fungsi PDF dari dua topan ini (Gambar 9 ), diamati bahwa distribusi fitur keseluruhan secara umum konsisten dengan set pelatihan. Namun, ada perbedaan penting dalam beberapa fitur individual. Misalnya, nilai movespeed_u(−1d) (Gambar 9k ) untuk kejadian TCER yang terkait dengan dua TC ini terkonsentrasi dalam rentang [−5, 0], sedangkan untuk sampel pelatihan, nilainya berada dalam rentang [−10, 0]. Ini menunjukkan bahwa sampel verifikasi memiliki kecepatan gerakan yang lebih lambat. Contoh lain adalah nilai 500hPa_thetae(0d) (Gambar 9l ) untuk kejadian TCER dari dua topan ini terkonsentrasi dalam rentang [350, 360], dibandingkan dengan rentang [340, 360] untuk sampel pelatihan, yang menunjukkan bahwa sampel verifikasi memiliki energi termal dan tidak stabil yang lebih tinggi. Perbedaan ini kemungkinan berkontribusi pada bias dalam prediksi model.
Singkatnya, Model No. 7-XGB, yang dibangun dengan rangkaian variabel fitur yang sama dengan model klasifikasi optimal di Bagian 3.1 , memiliki kemampuan peramalan yang sangat baik untuk TCER. Analisis SHAP mengungkap fitur-fitur utama yang berbeda untuk kejadian dan besarnya TCER. Dalam studi kasus “Chaba” dan “Doksuri”, model tersebut mengungguli data TIGGE tetapi menunjukkan beberapa bias. Fungsi PDF topan mengungkap perbedaan dalam fitur-fitur individual yang berkontribusi terhadap bias prediksi.
4 Kesimpulan dan Pembahasan
Studi ini mengembangkan kerangka kerja pembelajaran mesin (ML) untuk memprediksi kejadian hujan ekstrem akibat siklon tropis (TCER) dan mengukur besarnya di Guangxi (GX), Tiongkok. Dengan mengintegrasikan variabel fisik multiskala secara cermat dan secara efektif mengatasi tantangan utama seperti ketidakseimbangan data dan interpretabilitas model, penelitian ini secara signifikan memajukan kemampuan prediksi TCER sekaligus menjembatani kesenjangan antara aplikasi ML dan teori meteorologi. Temuan utama berikut diperoleh dari studi ini:
Berdasarkan data lintasan dari 149 topan yang diberi nama dari tahun 1981 hingga 2020, data presipitasi dari 91 stasiun pengamatan, serta berbagai variabel atmosfer, fitur topografi, dan karakteristik lintasan TC, studi ini menyusun matriks prediksi berdimensi tinggi yang berisi 212 variabel yang mencakup indeks dinamis, termodinamika, kelembapan, ketidakstabilan, dan sinyal prekursor (misalnya, perubahan intensitas yang tertunda). Selanjutnya, tiga algoritma pembelajaran terbimbing—Random Forest (RF), Adaptive Boosting (AdaBoost), dan Extreme Gradient Boosting (XGBoost)—digunakan untuk menangani klasifikasi biner, yang bertujuan untuk membedakan kejadian TCER dari kejadian non-TCER, dan tugas pemodelan regresi, yang berfokus pada kuantifikasi besaran curah hujan harian yang terkait dengan kejadian TCER. Untuk mengurangi redundansi fitur, lima metode pemilihan fitur diterapkan, yaitu Recursive Feature Elimination with Cross-Validation (RFECV), SelectFromModel (SFM), SelectFromModel combined with LassoCV (SFM-Lasso), SelectKBest, dan SequentialFeatureSelector (SFS). Selain itu, untuk mengatasi masalah ketidakseimbangan kelas, di mana kasus non-TCER lebih dominan, strategi algoritma resampling hibrida diadopsi, termasuk teknik seperti Synthetic Minority Over-sampling Technique (SMOTE) dan Adaptive Synthetic Sampling Approach (ADASYN). Selain itu, interpretabilitas model ditingkatkan melalui pemanfaatan SHapley Additive exPlanations (SHAP) dan optimasi melalui Genetic Algorithm (GA).
Dalam analisis komparatif klasifikasi biner dari kejadian TCER, model XGBoost menunjukkan ketahanan yang lebih kuat dalam menangani tugas klasifikasi biner yang melibatkan data yang tidak seimbang. Dengan Skor Ancaman (TS) rata-rata sebesar 0,37, model ini secara signifikan mengungguli model RF dan AdaBoost. Melalui integrasi metode pemilihan fitur dan Algoritma Genetika (GA), jumlah variabel prediktif secara efektif dikurangi. Model optimal akhirnya menggabungkan 18 variabel prediktif. Hal ini tidak hanya meningkatkan interpretabilitas model tetapi juga mempertahankan tingkat kinerja prediksi tertentu, dengan skor TS-nya mencapai 0,41.
Analisis SHAP mengungkap bahwa Jarak ke Jalur adalah faktor terpenting yang memengaruhi terjadinya peristiwa TCER. Hal ini berkorelasi negatif dengan terjadinya peristiwa TCER, yang konsisten dengan temuan penelitian sebelumnya. Perubahan fluks uap air tingkat rendah ( 850hPa_qv(0d)-(−1d) ) memberikan dampak positif yang signifikan pada peristiwa TCER, yang menunjukkan bahwa peningkatan transportasi uap air tingkat rendah memberikan kondisi air yang diperlukan untuk konveksi. Lebih jauh, variabel seperti fluks uap air horizontal pada 925-hPa ( 925hPa_qu(0d) ), geser angin vertikal zonal 1 hari sebelumnya ( vws_u(−1d) ), dan suhu potensial ekuivalen pada 500-hPa ( 500hPa_thetae(0d) ) juga memainkan peran penting dalam model tersebut. Gerakan menaik pada 500-hPa (w(0d)) meningkatkan ketidakstabilan, sesuai dengan termodinamika TC klasik. Faktor pemaksaan skala besar, seperti Western Pacific Subtropical High ( wpsh_area(0d)-(−1d) ), memodulasi transportasi kelembapan dan pola pemblokiran, yang menguatkan mekanisme TCER skala sinoptik. Variabel yang tertunda waktu dan variabel evolusi waktu mampu menangkap sinyal prekursor kejadian TCER, termasuk akumulasi kelembapan, penyesuaian sirkulasi, dan perubahan intensitas TC, yang selanjutnya menunjukkan efektivitas model dalam memperhitungkan faktor-faktor ini.
Dalam analisis komparatif model regresi untuk besaran TCER, model XGBoost juga menunjukkan kinerja yang sangat baik dalam memprediksi jumlah presipitasi TC. Model XGBoost yang optimal (Model No. 7-XGB), yang memiliki fitur yang sama dengan model klasifikasi yang optimal, memamerkan keterampilan prediktif yang kuat dengan Root Mean Square Error (RMSE) uji sebesar 13,57 dan skor TS sebesar 0,49 untuk kejadian tingkat hujan badai. Penggerak utama yang diidentifikasi meliputi anomali kecepatan vertikal ( 500hPa_w(0d) ), fluks kelembapan lapisan batas ( 925hPa_qu(0d) ), dan kecepatan translasi TC ( movespeed(−2d) ). Studi kasus Topan Chaba (2022) dan Doksuri (2023) mengungkapkan bahwa model tersebut mengungguli kumpulan data TIGGE dalam menangkap pola curah hujan ekstrem. Namun, model tersebut menunjukkan beberapa estimasi berlebihan yang terlokalisasi, yang dapat dikaitkan dengan sensitivitasnya terhadap gerakan badai dan perubahan sirkulasi.
Studi ini berhasil menjembatani kesenjangan antara prediksi TCER yang digerakkan oleh ML dan meteorologi fisik. Dengan mengintegrasikan variabel yang mengalami jeda waktu, model tersebut mampu menangkap evolusi intensitas TC dan prakondisi lingkungan—peningkatan yang nyata dibandingkan prediktor statis. Penekanan pada sinyal prekursor sejalan dengan paradigma peramalan operasional, di mana waktu tunggu dan ambang batas dinamis sangat penting. Selain itu, pendekatan multilevel untuk mengatasi ketidakseimbangan kelas, yang melibatkan pengambilan sampel ulang, penyesuaian algoritmik, dan integrasi ensembel, memberikan cetak biru yang berharga untuk prediksi kejadian langka di bidang meteorologi. Efektivitas XGBoost dalam menangani data yang tidak seimbang menyoroti kegunaannya dalam aplikasi cuaca ekstrem. Selain itu, kemampuan adaptasi kerangka kerja, seperti pengoptimalan fitur menggunakan GA, menjanjikan tugas peramalan cuaca berdampak tinggi lainnya, termasuk konveksi kuat dan prediksi kekeringan. Ini juga menawarkan referensi yang berharga untuk mengatasi masalah ketidakseimbangan di bidang penelitian serupa.
Meskipun demikian, penting untuk menyadari bahwa studi ini memiliki keterbatasan tertentu. Performa model secara khusus disesuaikan dengan karakteristik geografis GX yang unik, seperti interaksinya dengan Teluk Beibu dan Dataran Tinggi Yunnan-Guizhou. Oleh karena itu, memvalidasi generalisasinya ke wilayah lain, seperti Tiongkok Tenggara, sangatlah penting. Mengenai ketergantungan fitur, sementara SHAP secara efektif meningkatkan interpretabilitas model, pengecualian proses mikrofisika (misalnya, kandungan es awan) berpotensi membatasi kelengkapan mekanistik. Dalam hal integrasi operasional, meskipun model mengungguli dataset TIGGE, keberadaan bias residual, seperti yang dicontohkan oleh kasus Doksuri, menyoroti kebutuhan mendesak untuk perbaikan lebih lanjut. Ada persyaratan mendesak untuk pengembangan kerangka kerja ML-NWP hibrida untuk mengatasi bias ini dan meningkatkan kinerja model secara keseluruhan dalam aplikasi praktis.
Meskipun ada keterbatasan ini, kerangka kerja saat ini memiliki beberapa fitur yang menguntungkan. Desain modularnya, yang mencakup pemilihan fitur, resampling hibrid, dan interpretabilitas yang digerakkan oleh SHAP, memberikan landasan yang kuat untuk adaptasinya ke wilayah pesisir lainnya. Misalnya, penekanan pada sinyal prekursor, seperti fluks kelembapan yang tertunda waktu, selaras dengan mekanisme curah hujan TC yang diamati di Tiongkok Tenggara. Di wilayah ini, proses sektor hangat yang serupa memainkan peran dominan, yang menunjukkan bahwa kerangka kerja tersebut dapat diterapkan dengan modifikasi yang sesuai. Pekerjaan di masa mendatang akan difokuskan pada validasi kerangka kerja di seluruh cekungan dengan klimatologi yang berbeda (misalnya, Tiongkok Tenggara).