ABSTRAK
Pandemi COVID-19 telah menimbulkan dampak global yang signifikan terhadap kesehatan dan masyarakat, sehingga memerlukan analisis komprehensif terhadap faktor-faktor yang memengaruhinya, termasuk variabel cuaca. Studi ini menyelidiki interaksi antara kondisi meteorologi dan penyebaran COVID-19 di tiga wilayah Italia: Lombardia, Emilia-Romagna, dan Puglia. Efek variabel cuaca, seperti suhu udara, kelembapan relatif, titik embun, radiasi matahari, kecepatan angin, dan tekanan barometrik, dieksplorasi dalam kejadian penyakit. Data meteorologi dan kesehatan yang diamati diambil dari berbagai sumber, seperti Asosiasi Jaringan Meteorologi sains warga dan Departemen Perlindungan Sipil Nasional, dan dianalisis dengan metode statistik dan algoritma pembelajaran mesin. Studi ini menekankan perlunya mempertimbangkan secara cermat kuantitas meteorologi utama sebagai pendorong utama dalam strategi penyebaran dan pencegahan penyakit, yang menawarkan wawasan berharga untuk mengatasi tantangan pandemi dan memastikan keselamatan masyarakat global. Hasilnya mengungkapkan korelasi yang signifikan antara variabel atmosfer tertentu dan penyebaran COVID-19, dengan suhu titik embun sebagai parameter yang paling berpengaruh pada nilai suhu udara rendah.
1 Pendahuluan
Pandemi COVID-19, yang disebabkan oleh virus corona baru SARS-CoV-2, telah menjadi salah satu krisis kesehatan global paling serius dalam dekade terakhir. Diidentifikasi pertama kali di Wuhan (Tiongkok) pada akhir tahun 2019, infeksi tersebut dengan cepat menyebar ke seluruh dunia, yang menyebabkan Organisasi Kesehatan Dunia (WHO) mengumumkan pandemi global pada 11 Maret 2020. COVID-19 telah memengaruhi jutaan orang, menyebabkan dampak signifikan pada kesehatan, ekonomi, dan masyarakat. Responsnya melibatkan tindakan penahanan yang ketat, kampanye vaksinasi massal, dan upaya berkelanjutan untuk mengembangkan perawatan yang efektif. Mempertimbangkan dampak global dari infeksi tersebut, muncul pertanyaan tentang faktor-faktor mana yang berkontribusi terhadap penyebaran penyakit, dengan perhatian khusus difokuskan pada kondisi iklim.
COVID-19 termasuk dalam keluarga virus yang memicu sindrom pernapasan akut berat (SARS): risikonya terletak pada kemampuan umum untuk ditularkan dari orang ke orang melalui udara, dan gejalanya mirip dengan influenza, sementara pada kasus yang parah, kesulitan pernapasan, pneumonia, kegagalan multi-organ, dan kematian bahkan dapat terjadi. Seperti SARS, COVID-19 dapat berkorelasi kuat dengan faktor meteorologi seperti suhu, kelembaban, radiasi matahari, dan kecepatan angin: aspek-aspek ini memengaruhi penularan, stabilitas lingkungan, dan vitalitas virus. Variabel meteorologi sebenarnya memiliki pengaruh ganda pada patogen: di satu sisi, mereka secara langsung memengaruhi kelangsungan hidup, reproduksi, dan siklus hidup mereka, sementara, di sisi lain, dengan memengaruhi lingkungan, mereka secara tidak langsung mengondisikan habitat mereka.
Studi literatur telah menunjukkan bahwa timbulnya, perkembangan, kelangsungan hidup, dan penyebaran penyakit, terutama yang menular, seperti 229E (alpha coronavirus), SARS-CoV (Severe Acute Respiratory Syndrome Coronavirus), dan MERS-CoV (Middle East Respiratory Syndrome Coronavirus), berkorelasi erat dengan suhu dan kelembaban relatif (Chan et al. 2011 ; Geller et al. 2012 ; van Doremalen et al. 2013 ; Pirouz et al. 2020a ; Pirouz et al. 2020b ). Misalnya, Qi et al. ( 2020 ) menguji validitasnya pada kasus COVID-19 di 30 provinsi Tiongkok, yang menunjukkan bahwa suhu dan kelembaban memiliki dampak signifikan pada kasus COVID-19 yang terdaftar setiap hari. Penelitiannya mengungkap bahwa kombinasi peningkatan suhu harian sebesar 1°C, ketika kelembaban relatif berada di antara 67% hingga 86%, menurunkan angka harian kasus COVID-19 hingga 36%–57%, sementara peningkatan kelembaban relatif sebesar +1%, ketika suhu rata-rata harian berada di antara 5°C hingga 8°C, menurunkan kasus harian COVID-19 hingga 11%–22%.
Lebih jauh lagi, di antara komunitas ilmiah, telah banyak diskusi tentang pengaruh suhu terhadap penularan COVID-19 di beberapa negara dengan iklim hangat selama tahun epidemi 2020 (Demongeot et al. 2020 ; Iqbal et al. 2020 ; Mecenas et al. 2020 ). Meskipun spekulasi awal bahwa iklim hangat dan lembap dapat memperlambat penyebaran virus, fakta kemudian menunjukkan bahwa COVID-19 dapat menyebar dengan cepat dan luas di semua jenis iklim, termasuk yang panas dan lembap seperti di India (Vinoj et al. 2020 ). Selain itu, Gupta et al. ( 2020 ) mengonfirmasi bahwa suhu dan kelembapan adalah kuantitas yang cocok dalam memprediksi penularan COVID-19 di Amerika Serikat juga; Wu et al. ( 2020 ) menguji pengaruh faktor meteorologi terhadap kematian COVID-19, mengungkap korelasi positif signifikan dengan suhu siang hari dan korelasi negatif dengan kelembapan, sementara Sahin ( 2020 ) menyoroti korelasi positif antara tingkat penularan COVID-19 dan variabel meteorologi seperti suhu harian dan kecepatan angin, menekankan bagaimana faktor terakhir ini memengaruhi penularan virus dengan jeda waktu dua minggu. Patogen sebenarnya dapat menyebar dari daerah endemis ke daerah lain melalui badai angin dan debu, seperti dalam kasus wabah flu burung yang berkembang di beberapa daerah yang terkena angin, terutama selama musim badai debu, atau melalui pengangkutan virus influenza selama bulan-bulan musim dingin dari Asia ke Amerika.
Namun demikian, tidak ada kesimpulan umum yang telah ditarik, dan temuan yang berbeda diperoleh di seluruh dunia. Chin et al. ( 2020 ) menyatakan bahwa virus sangat stabil pada suhu 4 °C, tetapi lebih sensitif terhadap suhu panas. Sebaliknya, Zhu et al. ( 2020 ) menemukan bahwa suhu memiliki korelasi positif dengan kasus COVID-19 ketika di bawah 3 °C, sementara Shi et al. ( 2020 ) menunjukkan efek yang berlawanan di Tiongkok, yang menyatakan bahwa suhu antara 8 °C dan 10 °C mengurangi kemungkinan peningkatan harian dalam kasus COVID-19. Di Brasil, Prata et al. ( 2020 ) menunjukkan bahwa kenaikan suhu sebesar 1 °C dikaitkan dengan penurunan 4,9% dalam penularan COVID-19 harian ketika nilainya di bawah 25,8 °C. Terakhir, tingkat kelembapan yang rendah dan suhu dingin tampaknya secara signifikan mempengaruhi kelangsungan hidup dan penyebaran berbagai jenis virus pernapasan, dengan influenza menjadi contoh tipikal karena penyebarannya telah meningkat secara signifikan.
Dalam konteks ini, studi kami mengusulkan investigasi mendalam untuk mengidentifikasi apakah dan faktor cuaca mana di antara tekanan barometrik, suhu udara, kelembaban relatif, suhu titik embun (selanjutnya disebut titik embun), radiasi matahari yang masuk, dan kecepatan angin yang paling memengaruhi penularan COVID-19 di tiga wilayah Italia: Lombardia dan Emilia-Romagna di utara, dan Puglia di selatan, untuk memastikan apakah variabel meteorologi yang berpengaruh konsisten atau bervariasi berdasarkan kondisi cuaca di setiap wilayah. Berdasarkan asumsi yang dipelajari dari literatur ilmiah, diharapkan bahwa beberapa hubungan antara COVID-19 dan fitur meteorologi selama periode pandemi juga diamati di Italia. Hubungan ini di sini diperiksa menggunakan algoritma kecerdasan buatan yang didukung oleh penerapan model dekomposisi data; yang terakhir ini memungkinkan untuk memperoleh komponen tren untuk data yang diperiksa, sehingga menghilangkan kebisingan dan musim.
2 Bidang Studi
Fokus penelitian ini adalah pada tiga wilayah di Italia: Lombardia, Emilia-Romagna, dan Puglia. Gambar 1 menunjukkan area penelitian dengan lokasi stasiun cuaca terpilih oleh Meteonetwork (MNW).
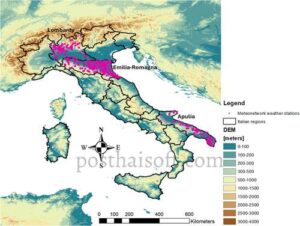
Kasus pertama COVID-19 tercatat pada bulan Februari 2020 di Lombardia, yang merupakan wilayah Italia dengan populasi terbesar (9.981.554) menurut ISTAT ( 2024 ) (Institut Statistik Nasional Italia: https://www.istat.it/ diakses pada 1 Juli 2024). Terletak di barat laut semenanjung Italia, Lombardia sebagian besar terdiri dari dataran (47%) bersama dengan daerah pegunungan (41%). Iklimnya kompleks karena fitur alam yang beragam, seperti keberadaan sungai, danau, dan gunung. Seperti di seluruh Italia utara, iklim Lombardia sangat dipengaruhi oleh Pegunungan Alpen di utara dan angin Mediterania dari selatan. Meskipun termasuk dalam zona iklim sedang, Lembah Po adalah daerah transisi antara Laut Mediterania, dan iklim kontinental dan samudra di Eropa tengah dan barat. Namun, orografi Alpen yang kompleks bertindak sebagai penghalang bagi angin dingin dan lembab dari utara dan Samudra Atlantik, yang menghasilkan komponen kontinental yang jelas; akibatnya, terjadi variasi suhu tahunan yang signifikan, dengan musim dingin yang dingin dan musim panas yang sangat panas. Terakhir, saat seseorang naik ke ketinggian, iklim menjadi dominan pegunungan, meskipun dengan karakteristik yang berbeda antara Pegunungan Alpen dan Pegunungan Apennini, terutama yang berkaitan dengan rezim presipitasi (ARPA 2024 , Badan Perlindungan Lingkungan Regional: https://www.arpalombardia.it/temi-ambientali/meteo-e-clima/clima/il-clima-in-lombardia/ diakses pada 1 Juli 2024).
Emilia-Romagna (dengan 4.458.006 penduduk) termasuk wilayah utara Italia, sebagian besar bercirikan dataran (48%), perbukitan (27%) dan pegunungan (25%). Iklimnya sebagian besar subkontinental, dengan musim dingin yang dingin dan musim panas yang panas. Namun, terdapat variasi iklim yang signifikan antara tempat-tempat yang berbeda di wilayah tersebut. Di daerah pegunungan Apennini, iklimnya lebih dingin, dan curah hujannya bisa melimpah, terutama selama musim dingin. Di dataran dan daerah pesisir, musim dinginnya bisa lebih sejuk, dan musim panasnya lebih panas, dengan pengaruh Laut Adriatik yang lebih besar. Curah hujan didistribusikan secara merata sepanjang tahun, meskipun mungkin ada periode kering selama musim panas (ARPAE 2024 , Badan Perlindungan Lingkungan Regional: https://www.arpae.it/it/temi-ambientali/clima/rapporti-e-documenti/atlante-climatico/ diakses pada 1 Juli 2024; Antolini et al. 2017 ).
Wilayah terakhir yang diteliti adalah Puglia (dengan 3.933.777 penduduk), yang terdiri dari 53% dataran, 45,5% perbukitan, dan hanya 1,5% pegunungan. Terletak di tenggara semenanjung Italia, wilayah ini berbatasan dengan Laut Adriatik di timur laut, dan Laut Ionia di selatan. Iklimnya biasanya Mediterania, ditandai dengan musim panas yang cukup hangat dan kering, musim dingin yang sejuk dan cukup hujan, dan curah hujan yang melimpah selama musim gugur (ISPRA, Institut Nasional Italia untuk Perlindungan dan Penelitian Lingkungan: https://www.isprambiente.gov.it/it diakses pada 1 Juli 2024).
3 Bahan dan Metode
Bagian ini menggambarkan data meteorologi dan epidemiologi yang digunakan untuk analisis saat ini, dengan deskripsi terperinci mengenai metodologi yang diterapkan.
3.1 Data Meteorologi
Pengamatan meteorologi yang digunakan dalam studi ini diambil dari jaringan data cuaca terbuka berbasis komunitas sains warga yang dikelola oleh Meteonetwork, asosiasi meteorologi Italia yang berbagi lebih dari 6500 data stasiun cuaca di seluruh benua Eropa, dengan kepadatan lebih tinggi di Italia. Secara khusus, lebih dari 4700 situs memperbarui basis data mereka setiap hari, dan 3400 dapat diakses secara real-time di situs web ini: https://www.meteonetwork.it/rete/livemap/ (diakses pada 1 Juli 2024). Untuk informasi lebih lanjut tentang jaringan MNW, sistem data cuacanya, prosedur kendali mutu, metadata, dll., pembaca dapat merujuk ke Giazzi et al. ( 2022 ).
Dalam makalah ini, data meteorologi yang dianalisis mencakup rentang dari 24 Februari 2020 (segera setelah wabah COVID-19 di Italia) hingga 31 Agustus 2023: dengan demikian, lebih dari 3 tahun tersedia untuk menghitung statistik utama dan investigasi bioklimatologi. Variabel meteorologi utama dikumpulkan pada langkah waktu per jam, khususnya, suhu udara 2 m (T) [°C], kelembaban relatif 2 m (RH) [%], titik embun 2 m (DEW) [°C], radiasi matahari gelombang pendek yang masuk (RAD) [W/m2], kecepatan angin (W) [m/s], dan tekanan barometrik berkurang di permukaan laut (BARO) [hPa], dan kemudian dirata-ratakan pada skala harian. Sebanyak 363 lokasi meteorologi dipilih dari tiga wilayah utama Italia (Tabel 1 ): Lombardia (98), Emilia-Romagna (188), dan Puglia (77).
TABEL 1. Distribusi stasiun cuaca MNW untuk setiap provinsi di Italia.
| Lombardia (98) | Emilia-Romagna (188) | Puglia (77) |
|---|---|---|
| Bergamo (18), Brescia (8), Como (9), Cremona (2), Lecco (4), Lodi (4), Mantova (4), Milano (13), Monza (17), Pavia (5), Sondrio (5), Varese (9). | Bologna (28), Ferrara (45), Forlì-Cesena (21), Modena (30), Parma (12), Piacenza (15), Ravenna (15), Reggio Emilia (7), Rimini (15). | Bari (19), Barletta-Andria-Trani (4), Brindisi (14), Foggia (9), Lecce (27), Taranto (4). |
3.2 Data Epidemiologi
Bahasa Indonesia: Selain data meteorologi, dua variabel kunci (selanjutnya disebut variabel target) yang terkait dengan infeksi disertakan dan diperoleh dari basis data Departemen Perlindungan Sipil Nasional: https://github.com/pcm-dpc/COVID-19 (diakses pada 1 Juli 2024): secara rinci, (i) jumlah kasus positif per 100.000 penduduk, yang diperoleh dengan membagi kasus positif yang tercatat setiap hari (terlepas dari status rawat inap) dengan data populasi dari ISTAT masing-masing wilayah dan mengalikan hasilnya dengan 100.000; (ii) jumlah individu yang dirawat di rumah sakit dengan gejala. Informasi mengenai penularan dapat diakses melalui dasbor geografis interaktif tempat nilai-nilai mengenai tren infeksi pada skala nasional, regional, dan distrik ditampilkan. Untuk memberikan gambaran yang jelas selama periode pandemi di negara Italia, grafik yang menggambarkan tren kasus positif per 100.000 penduduk dan individu yang dirawat di rumah sakit dengan gejala dari tahun 2020 hingga 2023 ditunjukkan pada Gambar 2 .
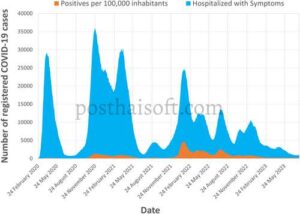
Catatan data meteorologi dan epidemiologi ini memungkinkan terciptanya basis data yang padat untuk menganalisis penyebaran COVID-19, menghitung jumlah kasus positif per 100.000 penduduk, dan individu yang dirawat di rumah sakit dengan gejala di tiga wilayah yang diselidiki.
3.3 Metodologi yang Diadopsi
Karena makalah ini bertujuan untuk mengidentifikasi faktor meteorologi mana yang berpotensi memengaruhi penyebaran virus, studi kami menyelidiki interaksi antara variabel cuaca dan insiden COVID-19 di wilayah yang dicirikan oleh fitur demografi dan kondisi iklim yang berbeda menggunakan model kecerdasan buatan (AI). Alur kerja metodologi yang diterapkan diilustrasikan dalam Gambar 3 dan dirangkum dalam empat langkah berikut.
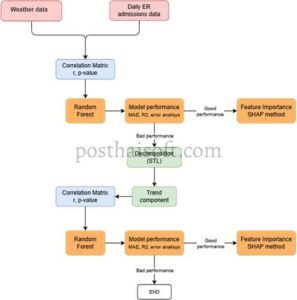
i. Pada tahap awal, analisis korelasi (Gogtay dan Thatte 2017 ) dilakukan antara variabel meteorologi dan variabel yang menjadi perhatian, yaitu rawat inap dengan gejala dan tingkat positif per 100.000 penduduk. Variabel-variabel tersebut dievaluasi melalui koefisien Pearson, yang mengukur hubungan antara dua set data: jika nilainya mendekati 1 (−1), artinya ada korelasi positif (negatif) yang kuat, dan kedua set data meningkat (menurun) secara bersamaan; jika nilainya mendekati 0, berarti tidak ada korelasi.
ii. Selanjutnya, fase pelatihan dan pengujian dengan model simulasi, berdasarkan metode supervised machine learning (ML) (Shetty et al. 2022 ), diimplementasikan. Dalam skenario ini, dataset COVID-19 (yaitu, rawat inap dengan gejala dan positif per 100.000 penduduk) adalah dua variabel target, sedangkan prediktor diwakili oleh data meteorologi. Algoritma, yang di sini digunakan untuk membangun model regresi, adalah Random Forest (RF) (Rodriguez-Galiano et al. 2015 ), yang secara umum efektif untuk memodelkan fenomena nonlinier, menghindari overfitting data. Proses ini selanjutnya dievaluasi dengan prosedur k-fold cross-validation yang memverifikasi apakah sampel awal mengalami overfitting.
iii. Jika hasil dari koefisien Pearson dan simulasi RF tidak memenuhi harapan (seperti yang terjadi), metodologi yang diuraikan melibatkan penerapan filter data menggunakan teknik statistik yang disebut Dekomposisi Musiman dan Tren dengan Loess (STL) (Cleveland et al. 1990 ). Prosedur ini Persamaan ( 1 ) memisahkan data menjadi komponen fundamentalnya (tren, musiman, dan residual) untuk menghilangkan gangguan intrinsik:
![]()
Di mana:
Y t adalah nilai teramati dari deret waktu pada waktu t ;
T t adalah komponen tren pada waktu t ;
S t adalah komponen musiman pada waktu t ;
R t adalah komponen residual (atau noise) pada waktu.
Model STL menggunakan regresi lokal berbobot yang kuat untuk dekomposisi deret waktu. Selama estimasi variabel target, subset titik data di dekat variabel yang diprediksi dipilih, dan regresi linier atau kuadrat dilakukan pada subset ini menggunakan kuadrat terkecil berbobot. Penggunaan STL diterapkan untuk memperoleh komponen tren baik untuk faktor meteorologi maupun kedua variabel target. Selanjutnya, analisis korelasi baru dilakukan lagi untuk mengetahui koefisien Pearson yang diinginkan.
iv. Terakhir, bobot setiap variabel dalam mendefinisikan model dinilai, yaitu seberapa besar setiap variabel independen akan memengaruhi variabel target. Hal ini dicapai melalui penerapan metode SHAP (SHapley Additive exPlanation) (Mangalathu et al. 2020 ; Nohara et al. 2022 ), pendekatan Kecerdasan Buatan yang Dapat Dijelaskan (XAI) yang populer (Barredo et al. 2020 ), yang umumnya digunakan dalam teori permainan. Metode SHAP menghitung nilai Shapley untuk setiap fitur i dalam model, menurut Persamaan ( 2 ):
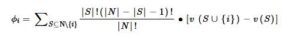
Di mana:
ϕ i adalah nilai Shapley untuk fitur i ;
N adalah himpunan semua fitur;
S merupakan bagian dari fitur yang tidak termasuk i ;
v (S) adalah fungsi nilai (prediksi model ) untuk subset S.
Tujuan utama metode XAI adalah membuat fungsi model kecerdasan buatan menjadi transparan, menghindari apa yang disebut proses kotak hitam. Dengan menggunakan metode XAI, penting untuk memverifikasi setiap variabel yang diamati dan menyimpulkan apakah, menurut model, variabel tersebut dapat memengaruhi nilai yang diprediksi; berdasarkan asumsi ini, keandalan model dapat diperkirakan.
4 Hasil
Hasil dari empat langkah yang disorot dalam metodologi disajikan dalam bagian ini. Bagian pertama analisis dilakukan tanpa menerapkan model STL, yang umumnya memperoleh skor buruk untuk simulasi model RF dan dengan validasi silang k-fold. Setelah fungsi dekomposisi diterapkan dan hasil yang lebih baik tercapai, penyelidikan dilanjutkan dengan memperkenalkan metode SHAP untuk menentukan Pentingnya Fitur faktor meteorologi pada dua variabel target selama periode 24 Februari 2020 hingga 31 Agustus 2023.
4.1 Analisis Awal
Tahap awal penelitian ini mengevaluasi hubungan antara variabel meteorologi dan epidemiologi terpilih di wilayah penelitian Lombardia, Emilia-Romagna, dan Puglia. Dengan menghitung koefisien korelasi Pearson dan matriks korelasi terkait dengan nilai p yang ditetapkan sebesar 0,01, signifikansi statistik korelasi ditentukan.
Selanjutnya, model pembelajaran mesin (regresor Hutan Acak) diterapkan untuk mensimulasikan evolusi data epidemiologi selama keseluruhan periode; ini melibatkan pembagian kumpulan data menjadi dua bagian: satu untuk melatih model (80%), dan yang lainnya untuk pengujian (20%).
Selain itu, kebaikan model dinilai menggunakan metode cross-validation dengan teknik k-fold dengan k sama dengan 10 pada seluruh dataset. Cross-validation adalah metode statistik yang digunakan untuk mengevaluasi kemampuan generalisasi model machine learning, yaitu kemampuannya untuk memprediksi data baru yang tidak terlihat selama fase pelatihan. Dengan demikian, model dilatih sebanyak k kali, setiap kali menggunakan k-1 fold untuk pelatihan dan fold yang tersisa untuk pengujian. Proses ini membantu mengurangi kesalahan karena variabilitas dalam data pelatihan/uji, menghindari overfitting, memberikan estimasi kinerja model yang lebih andal untuk nilai-nilai baru, dan memastikan bahwa kinerja model tidak bergantung pada interval split antara data pelatihan dan uji.
Performa fase pelatihan/uji model RF prediktif dan k-fold cross-validation dinilai melalui beberapa indeks statistik (Chicco et al. 2021 ), yang umum dikenal dalam literatur: koefisien determinasi ( R 2 ) dan Mean Absolute Error (MAE). Untuk k-fold cross-validation, MAE yang dihitung mempertimbangkan akurasi rata-rata model di seluruh bagian berbeda dari subset data pelatihan dan pengujian. Jika nilai cross-validasi berada dalam orde besaran yang sama dengan yang awalnya diperoleh dalam fase pengujian oleh model RF prediktif, performa model dapat dianggap dapat diterima.
Dalam pemeriksaan pendahuluan ini, baik analisis korelasi awal maupun penerapan model RF tidak menghasilkan hasil yang diinginkan: pada kenyataannya, korelasi yang diperoleh umumnya lemah, dengan nilai absolut koefisien Pearson jauh di bawah 0,5 (nilai magenta pada Tabel 2 ), yang menunjukkan tidak ada korelasi yang kuat antara variabel meteorologi yang dipilih dan dua variabel epidemiologi. Lebih jauh, nilai R 2 dan MAE yang tidak memuaskan, tidak dilaporkan di sini demi singkatnya, bahkan diperoleh untuk simulasi model RF dan dengan validasi silang k-fold.
TABEL 2. Hasil matriks korelasi untuk Lombardia, Emilia-Romagna, dan Puglia sebelum (berwarna magenta) dan sesudah (berwarna hijau) memperkenalkan metode STL untuk jumlah pasien yang dirawat di rumah sakit dengan gejala dan positif per 100.000 penduduk.
| Variabel cuaca | Lombardia | Emilia Romagna | Italia | |||
|---|---|---|---|---|---|---|
| Dirawat di rumah sakit dengan gejala | Positif per 100.000 penduduk | Dirawat di rumah sakit dengan gejala | Positif per 100.000 penduduk | Dirawat di rumah sakit dengan gejala | Positif per 100.000 penduduk | |
| BARO | 0,230 (0,150) | 0,390 (0,200) | 0,0001 (0,000) | 0,340 (0,190) | 0,190 (0,100) | 0,280 (0,140) |
| RH | -0,078 (-0,056) | 0,011 (−0,038) | 0,1900 (0,120) | 0,300 (0,190) | 0,260 (0,200) | 0,044 (0,012) |
| Bahasa Inggris: RAD | -0,080 (-0,080) | -0,280 (-0,230) | -0,350 (-0,320) | -0,270 (-0,240) | -0,340 (-0,310) | -0,180 (-0,160) |
| EMBUN | -0,450 (-0,410) | -0,380 (-0,350) | -0,610 (-0,580) | -0,380 (-0,350) | -0,490 (-0,430) | -0,460 (-0,410) |
| T | -0,360 (-0,350) | -0,330 (-0,310) | -0,560 (-0,540) | -0,390 (-0,370) | -0,460 (-0,450) | -0,350 (-0,340) |
| Kami | 0,0087 (0,056) | -0,230 (-0,099) | -0,190 (-0,002) | -0,230 (-0,060) | -0,0097 (0,025) | 0,110 (0,093) |
4.2 Metode STL
Mengikuti kerangka metodologi, metode STL diterapkan. Proses ini menyaring data prediktif melalui fungsi dekomposisi, yang memungkinkan data dibagi menjadi tiga komponen: musiman, tren, dan residual. Dengan menggunakan komponen tren, yang lebih mewakili perkembangan data dari waktu ke waktu, sub-himpunan data baru dibuat dengan nilai meteorologi dan epidemiologi; oleh karena itu, analisis baru dilakukan. Koefisien korelasi Pearson sekali lagi dihitung, tetapi kali ini nilai yang lebih baik (absolut), dibandingkan dengan yang diperoleh sebelumnya, tercapai (nilai hijau pada Tabel 2 ).
Selanjutnya, kami menerapkan model pembelajaran mesin terbimbing menggunakan algoritma regresi RF dalam fase pelatihan dan pengujiannya, tetapi sekarang dijalankan menggunakan dataset harian ini, yang dibuat dengan variabel tren yang diperoleh dari model dekomposisi STL. Kinerjanya kembali dievaluasi menggunakan metrik R 2 dan MAE untuk jumlah pasien yang dirawat di rumah sakit dengan gejala dan kasus positif per 100.000 penduduk (masing-masing empat kolom pertama Tabel 3 dan 4 ). Skor yang sangat tinggi mendorong kami untuk menggunakan model regresor pada seluruh simulasi rangkaian data, dengan demikian mengevaluasi kinerja keseluruhannya (Gambar 4-6 ) . Perbedaan kecil terlihat antara nilai simulasi dan nilai terukur untuk dua variabel target, yang menunjukkan bahwa model tersebut mensimulasikan tren data yang diamati dengan baik. Seluruh simulasi kemudian dinilai dengan k-fold cross-validation (empat kolom kedua dalam Tabel 3 dan 4 ), di mana skor keterampilan yang dicapai konsisten dengan skor yang awalnya diperoleh dalam fase pengujian oleh model RF prediktif, yang menyoroti kekokohan model, dan menunjukkan tidak adanya fenomena overfitting.
TABEL 3. Hasil fase pelatihan/pengujian kinerja model dan validasi silang k-fold di tiga wilayah Italia mengenai pasien rawat inap dengan gejala.
| Wilayah | kereta api R 2 | uji R 2 | kereta api MAE | uji MAE | R 2 berarti kereta api | Uji rata- rata R2 | MAE berarti kereta api | Uji rata-rata MAE |
|---|---|---|---|---|---|---|---|---|
| Lombardia | 0,991 tahun | 0,918 tahun | 0,008 | 0,022 | 0,993 | 0,946 tahun | -0,007 | -0,017 |
| Emilia Romagna | 0,994 tahun | 0,958 | 0,009 | 0,024 | 0,994 tahun | 0,966 tahun | -0,008 | -0,022 |
| Italia | 0,985 | 0.926 | 0,014 | 0,035 | 0,989 | 0.920 | -0,012 | -0,033 |
TABEL 4. Hasil fase pelatihan/pengujian kinerja model dan validasi silang k-fold di tiga wilayah Italia: positif per 100.000 penduduk.
| Wilayah | kereta api R 2 | uji R 2 | kereta api MAE | uji MAE | R 2 berarti kereta api | Uji rata- rata R2 | MAE berarti kereta api | Uji rata-rata MAE |
|---|---|---|---|---|---|---|---|---|
| Lombardia | 0,989 | 0.884 | 0,006 | 0,017 tahun | 0,993 | 0,949 tahun | -0,005 | -0,013 |
| Emilia Romagna | 0,992 | 0,964 tahun | 0,005 | 0,012 | 0,994 tahun | 0,963 | -0,004 | -0,010 |
| Italia | 0,982 | 0.880 | 0,016 | 0,044 tahun | 0,984 | 0.898 | -0,014 | -0,037 |



Terakhir, diagram sebar pada Gambar 7 – 9 merangkum kesesuaian antara data observasi dan simulasi untuk dua variabel target yang sedang diselidiki; pita kesalahan yang ditunjukkan sebagai tingkat keyakinan menunjukkan kinerja model RF.



Di tiga wilayah tersebut, sebagian besar titik berada dalam rentang galat ±20%, bahkan banyak yang berada dalam rentang ±10% untuk kedua variabel target. Di wilayah Lombardia dan Emilia-Romagna, terlihat jelas bagaimana titik-titik tersebut mengelompok di sekitar garis bagi, dan hanya beberapa di antaranya yang berada di luar tingkat keyakinan, sementara di wilayah Puglia, lebih banyak titik berada di luar rentang ±20%.
Selain itu, Tabel 5 menunjukkan analisis mendalam yang mempertimbangkan rentang kesalahan ±5% di tiga wilayah untuk jumlah pasien rawat inap dengan gejala dan hasil positif per 100.000 penduduk, dengan persentase poin di Lombardia masing-masing sebesar 78% dan 58%, sementara di Emilia-Romagna, sebesar 71% dan 52%; hanya di Puglia, persentasenya turun menjadi 63% dan 42%. Meskipun demikian, mayoritas poin umumnya terdistribusi dalam tingkat keyakinan di tiga wilayah, yang menunjukkan ketahanan model Random Forest yang diterapkan.
TABEL 5. Persentase titik data yang berada dalam rentang kesalahan ±5% untuk jumlah pasien yang dirawat di rumah sakit dengan gejala dan hasil positif per 100.000 penduduk di wilayah Lombardia, Emilia-Romagna, dan Puglia.
| Wilayah | Pasien yang dirawat di rumah sakit dengan gejala | Positif per 100.000 penduduk |
|---|---|---|
| Lombardia | 78% | 58% |
| Emilia Romagna | 71% | 52% |
| Italia | 63% | 42% |
4.3 Metode SHAP
Hasil yang memuaskan mendorong analisis menuju implementasi metode Feature Importance (FI) (Shaikhina et al. 2021 ; Kumar et al. 2020 ). Melalui prosedur perhitungan ini, bobot (atau kepentingan) diberikan pada setiap variabel meteorologi dalam keseluruhan proses pembelajaran mesin di tiga wilayah (Tabel 5–7 ). Langkah terakhir ini melibatkan prediktor yang diperoleh sebagai bobot setiap variabel dalam mendefinisikan model prediktif yang akan dievaluasi. Secara khusus, diperiksa seberapa besar setiap variabel independen (meteorologi) memengaruhi variabel dependen (target). Analisis ini dilakukan dengan menggunakan metode SHAP (SHapley Additive exPlanations) (Fryer et al. 2021 ; Roder et al., 2021), yang merupakan pendekatan terkonsolidasi untuk menjelaskan model pembelajaran mesin.
Hasil dari Pentingnya Fitur SHAP untuk pasien rawat inap dengan gejala (Tabel 6a ) di Lombardia menunjukkan bahwa variabel cuaca yang paling memengaruhi penularan COVID-19 adalah DEW, RAD, dan W, karena nilai normalisasi keenam variabel ini berjumlah 70% pengaruh, sementara faktor meteorologi yang paling memengaruhi penularan COVID-19 untuk positif per 100.000 penduduk (Tabel 6b ) adalah DEW, T, dan W. Hasil yang sama ditemukan untuk wilayah Emilia-Romagna dan Puglia, seperti yang ditunjukkan dalam Tabel 7 dan 8 ; dalam semua kasus, titik embun ternyata memiliki kepentingan utama.
TABEL 6. Pentingnya Fitur SHAP untuk wilayah Lombardia; jumlah pasien yang dirawat di rumah sakit dengan gejala (a) dan positif per 100.000 penduduk (b).
| Kepentingan relatif (a) | Kepentingan relatif (b) | ||
|---|---|---|---|
| EMBUN | 0.426 | EMBUN | 0,336 tahun |
| Bahasa Inggris: RAD | 0.229 | T | 0.180 |
| Kami | 0.161 | Kami | 0,176 tahun |
| BARO | 0,074 tahun | BARO | 0,146 tahun |
| RH | 0,061 tahun | RH | 0.116 |
| T | 0,047 tahun | Bahasa Inggris: RAD | 0,043 tahun |
TABEL 7. Pentingnya Fitur SHAP untuk wilayah Emilia Romagna; jumlah pasien yang dirawat di rumah sakit dengan gejala (a), positif per 100.000 penduduk (b).
| Kepentingan relatif (a) | Kepentingan relatif (b) | ||
|---|---|---|---|
| EMBUN | 0.471 | EMBUN | 0.414 |
| Bahasa Inggris: RAD | 0.213 | T | 0,168 |
| Kami | 0,095 | Kami | 0,145 |
| BARO | 0,090 | BARO | 0,134 tahun |
| RH | 0,078 tahun | RH | 0,087 tahun |
| T | 0,053 | Bahasa Inggris: RAD | 0,052 |
TABEL 8. Pentingnya Fitur SHAP untuk wilayah Puglia; jumlah pasien yang dirawat di rumah sakit dengan gejala (a), positif per 100.000 penduduk (b).
| Kepentingan relatif (a) | Kepentingan relatif (b) | ||
|---|---|---|---|
| EMBUN | 0,501 tahun | EMBUN | 0.451 |
| Bahasa Inggris: RAD | 0,155 | T | 0,158 |
| Kami | 0.141 | Kami | 0.127 |
| BARO | 0,073 tahun | BARO | 0.100 |
| RH | 0,069 tahun | RH | 0,094 tahun |
| T | 0,061 tahun | Bahasa Inggris: RAD | 0,071 tahun |
Selain itu, untuk mengevaluasi pentingnya waktu jeda pada dampak titik embun dengan penyebaran COVID-19 dan Risiko Relatif (RR) terkaitnya, DLNM (Distributed Lag Non-Linear Model) diimplementasikan dengan mengikuti metodologi yang diusulkan oleh Gasparrini ( 2011 ), Gasparrini ( 2021 ) dan Gasparrini 2021 , dengan jeda maksimum di sini ditetapkan pada 10 hari. RR adalah indeks yang mengukur probabilitas terjadinya suatu peristiwa dengan adanya paparan tertentu dibandingkan dengan ketidakhadirannya (McNutt et al. 2003 ). Ini dihitung dengan membandingkan probabilitas peristiwa (misalnya, peningkatan kasus COVID-19) yang terkait dengan tingkat paparan tertentu (dalam kasus kami nilai titik embun tertentu) dengan probabilitas peristiwa dalam kondisi referensi (misalnya, nilai rata-rata variabel meteorologi). Dalam membangun model, splines yang diberi penalti (Economou et al. 2024 ) digunakan untuk mengoptimalkan derajat kebebasan untuk variabel meteorologi dan waktu jeda. Parameter yang dioptimalkan ini kemudian diterapkan pada proses pemodelan, menghasilkan grafik yang menggambarkan RR sebagai fungsi variasi waktu jeda.
Berdasarkan grafik yang ditunjukkan pada Gambar 10 dengan referensi khusus pada nilai titik embun di wilayah Lombardia, waktu jeda yang terkait dengan RR tertinggi berbeda antara kedua kasus. Mengenai pasien yang dirawat di rumah sakit dengan gejala (Gambar 10a ), RR tertinggi diamati untuk jeda antara 0 dan 1 hari, sedangkan untuk hasil positif per 100.000 penduduk (Gambar 10b ), jeda yang signifikan ditemukan antara 0–1, 4–6, dan sekitar 10 hari; penting untuk dicatat bahwa skor RR tertinggi dikaitkan ketika suhu titik embun rendah diamati.

5 Diskusi
Infeksi COVID-19, yang disebabkan oleh virus corona baru SARS-CoV-2, dinyatakan sebagai pandemi oleh WHO pada bulan Maret 2020 setelah virus tersebut diidentifikasi di Wuhan (Tiongkok) pada akhir tahun 2019. Karena ini telah menjadi salah satu krisis kesehatan global paling serius dalam beberapa dekade terakhir, menilai dampak faktor meteorologi terhadap penyebaran COVID-19 telah mendorong komunitas ilmiah untuk menyelidiki beberapa metode dan analisis dalam beberapa tahun terakhir (Yuan et al. 2021 ; Balboni et al. 2023 ; Tan and Schultz 2023 ). Seperti disebutkan dalam pendahuluan, berbagai pencapaian telah ditemukan, tetapi tidak ada kesimpulan umum yang diperoleh di seluruh dunia.
Dalam makalah ini, kami menganalisis variabel meteorologi umum di tiga wilayah Italia: Lombardia, Emilia-Romagna, dan Puglia, menggunakan nilai meteorologi sains warga dari Meteonetwork dan data epidemiologi dari basis data perlindungan sipil nasional.
Awalnya, analisis korelasi awal antara data meteorologi dan nilai COVID-19 diterapkan, tetapi diperoleh hasil yang lemah antara kedua jenis data yang dianalisis. Dengan demikian, model dekomposisi STL diperkenalkan untuk menguraikan data meteorologi dan nilai terkait infeksi COVID-19 menjadi tiga komponennya: musim, tren, dan residual.
Menghilangkan noise dari deret waktu sangat penting untuk menyoroti tren, meningkatkan analisis data jangka panjang. Tanpa noise, menjadi lebih mudah untuk mengidentifikasi pola reguler dan meningkatkan akurasi prediksi. Proses ini tidak hanya memfasilitasi pemahaman hubungan antara variabel dan dinamika sistem, tetapi juga mengurangi risiko overfitting dalam model pembelajaran mesin, membuatnya lebih kuat dan cocok untuk menggeneralisasi data baru. Oleh karena itu, model pembelajaran mesin (RF) dijalankan lagi untuk mensimulasikan tren nilai yang diamati dibandingkan dengan sampel data yang dipilih secara acak. Setelah memperkenalkan STL, diamati bahwa: (i) data yang diprediksi mensimulasikan dengan baik tren data yang diamati; (ii) menganalisis hasil teknik k-fold cross-validation, R 2 dan MAE masing-masing mendekati 1 dan 0, yang menunjukkan model yang diterapkan kuat; (iii) masalah overfitting tidak ditemukan, karena setelah fase uji model, diamati bahwa metrik rata-rata k-fold cross-validation sejalan dengan, dan bahkan lebih baik daripada yang awalnya diperoleh oleh model RF prediktif; (iv) menganalisis diagram sebar pada Gambar 7 – 9 , sebagian besar titik yang mewakili data observasi vs. data simulasi berada dalam ±10% rentang galat, dengan lebih dari 75% dalam tingkat keyakinan ±5%, dan sangat sedikit yang berada di luar rentang ±20%, terutama di wilayah Lombardia dan Emilia-Romagna, sementara penurunan diamati di Puglia untuk data dalam rentang galat ±5%, yang mana persentasenya turun menjadi 63% untuk pasien rawat inap dengan gejala dan menjadi 42% untuk kasus positif per 100.000 penduduk, masing-masing.
Namun, temuan utama studi ini muncul dari analisis Feature Importance (FI). Faktanya, penting untuk mengamati bahwa terkait pasien rawat inap dengan gejala dan kasus positif per 100.000 penduduk di tiga wilayah yang diteliti, variabel yang secara konsisten menunjukkan dampak terbesar pada penyebaran COVID-19 adalah titik embun.
Titik embun didefinisikan sebagai suhu yang harus dicapai udara untuk mencapai titik jenuh (pada tekanan konstan), yaitu mencapai 100% kelembapan relatif, yang menyebabkan uap air yang terkandung mengembun menjadi embun atau kabut. Ketika fenomena ini terjadi, titik embun sama dengan suhu udara, yang pada kenyataannya membawa kelembapan ke titik jenuh. Pencapaian ini mengungkap peran mendasar kelembapan atmosfer dalam penyebaran COVID-19: jika uap air mendekati titik jenuh, virus akan memiliki persistensi yang lebih besar di udara. Terperangkapnya droplet oleh kelembapan menciptakan, pada kenyataannya, kondisi ideal untuk penularan virus di antara manusia.
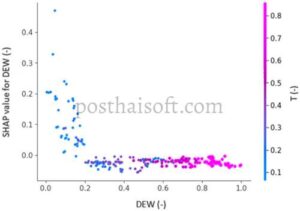
Oleh karena itu, nilai kelembaban relatif yang tinggi secara teoritis dapat memainkan peran penting dalam penyebaran COVID-19. Pada kenyataannya, faktor-faktor yang memengaruhi penyebaran virus banyak dan saling berhubungan, sehingga sulit untuk memisahkannya sebagai yang dominan, terutama mengingat bahwa kelembaban relatif tidak menunjukkan kepentingan fitur yang tinggi dalam kasus yang dianalisis. Di sisi lain, penularan sangat bergantung pada berbagi lingkungan dalam ruangan oleh individu juga, yang sering terjadi di musim dingin, dan berkurang secara signifikan selama musim panas, yang ditandai dengan suhu dan radiasi yang lebih tinggi. Sebagai contoh untuk pasien yang dirawat di rumah sakit dengan gejala di wilayah Lombardia, Gambar 11 menggambarkan plot ketergantungan SHAP dari titik embun dalam kaitannya dengan nilai suhu udara (keduanya dinyatakan dalam bentuk tanpa dimensi) dan mengungkapkan bahwa nilai indeks SHAP tertinggi (indikasi kinerja prediktif model) terjadi pada suhu rendah (ditunjukkan dalam titik biru) dengan nilai titik embun rendah, umumnya, di musim yang lebih dingin.
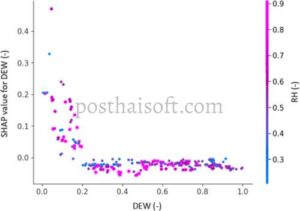
Temuan ini tidak begitu jelas dalam grafik titik embun yang sama dalam kaitannya dengan nilai kelembapan relatif, masih dalam bentuk tanpa dimensi (Gambar 12 ). Meskipun demikian, nilai SHAP secara umum lebih besar ketika tingkat kelembapan relatif yang lebih tinggi (warna magenta) terjadi pada titik embun rendah (pada bulan-bulan yang lebih dingin). Skor ini menggarisbawahi hasil yang orisinal dan signifikan, yang juga berguna dalam memandu penelitian di masa mendatang.
5.1 Keterbatasan Penelitian
Studi yang diusulkan menyajikan beberapa keterbatasan metodologis yang perlu diperhatikan. Secara khusus, tidak ada perbedaan temporal yang dibuat antara periode pra dan pasca vaksin atau periode pra dan pasca jam malam. Pilihan ini dimotivasi oleh kebutuhan untuk menyimpan data dalam jumlah yang cukup untuk menerapkan teknik pembelajaran mesin. Membagi periode analisis menjadi terlalu banyak segmen kecil akan memperpendek ketersediaan data untuk setiap interval, sehingga mengorbankan keandalan dan ketahanan hasil. Demikian pula, tingkat vaksinasi belum dipertimbangkan secara eksplisit. Menyertakan variabel ini akan memerlukan fragmentasi data yang lebih rinci dan pembagian temporal dari periode yang dianalisis, yang selanjutnya mengurangi jumlah data yang dapat diakses untuk pelatihan model yang kuat. Masalah serupa muncul dengan usia, terutama dengan adanya beberapa penyakit penyerta. Meskipun merupakan variabel yang relevan, variabel ini belum secara eksplisit dimasukkan dalam model. Oleh karena itu, keputusan untuk tidak secara eksplisit mempertimbangkan usia dan penyakit penyerta sesuai dengan pendekatan metodologis yang ditujukan untuk mempertahankan kumpulan data besar yang memastikan model yang kuat dan prediktif. Namun, model statistik-probabilistik hibrida masa depan yang dikombinasikan dengan teknik pembelajaran mesin dapat diterapkan untuk mengatasi keterbatasan terkait data besar ini, yang memungkinkan analisis yang lebih bernuansa sambil mempertahankan ketahanan model prediktif.
Keterbatasan tambahan menyangkut tidak adanya investigasi khusus terhadap polutan udara. Sensor stasiun pemantauan yang digunakan dalam studi ini secara eksklusif bersifat meteorologis; akibatnya, analisis difokuskan pada aspek-aspek ini saja. Namun, di masa mendatang, untuk memberikan penilaian yang lebih komprehensif, data polutan udara dapat diintegrasikan. Misalnya, aspek lebih lanjut yang dapat dipertimbangkan untuk pengembangan di masa mendatang adalah dimasukkannya tinggi lapisan batas atmosfer (BLH) sebagai faktor meteorologi tambahan yang berpotensi memengaruhi penyebaran COVID-19. Parameter ini telah dianalisis dalam beberapa studi sebelumnya yang membandingkan kondisi meteorologi selama dan sebelum pandemi untuk menilai dampak variabilitas meteorologi selama periode tersebut (Petetin et al. 2020 ; García-Dalmau et al. 2022 ). BLH sebenarnya adalah variabel klasik yang dipertimbangkan dalam dispersi atmosfer polutan udara; dengan demikian, BLH juga dapat berperan dalam penyebaran COVID-19. Dengan cara yang sama, batasan mengenai kemungkinan pembenaran biologis dalam hubungan antara faktor meteorologi dan penyebaran COVID-19 belum dieksplorasi, karena faktor biologis berada di luar tujuan penelitian kami.
Sebagian besar pilihan metodologis di sini dibuat untuk memaksimalkan ketahanan dan keandalan model prediktif. Namun, kemungkinan untuk memperluas dan mengeksplorasi lebih jauh aspek-aspek ini dalam penelitian mendatang tentunya merupakan perkembangan masa depan yang perlu diselidiki.
6 Kesimpulan
Studi saat ini menganalisis pengaruh faktor meteorologi terhadap penularan COVID-19 di tiga wilayah Italia dengan kondisi iklim berbeda (Lombardia, Emilia-Romagna, dan Puglia).
Pertama, kami melakukan analisis korelasi awal antara data cuaca rata-rata harian dan variabel target kesehatan (jumlah orang yang dirawat di rumah sakit dengan gejala dan jumlah kasus positif per 100.000 penduduk), diikuti oleh analisis penyaringan data menggunakan dekomposisi STL. Nilai tren yang ditentukan melalui fungsi STL menjadi subjek penyelidikan kedua, yang mengungkapkan korelasi yang baik antara data meteorologi dan epidemiologi.
Untuk melanjutkan simulasi, algoritma Random Forest, yang merupakan model regresi berdasarkan algoritma pembelajaran mesin, diimplementasikan dan dievaluasi melalui perhitungan skor keterampilan, bahkan dengan prosedur validasi silang k-fold. Nilai R 2 dan MAE, masing-masing mendekati 1 dan 0, menyoroti keakuratan dan kekokohan model dalam mensimulasikan data terukur di seluruh periode observasi antara 24 Februari 2020 dan 31 Agustus 2023.
Akhirnya, pentingnya setiap variabel cuaca dinilai menggunakan metodologi SHAP, menemukan titik embun sebagai parameter meteorologi paling signifikan dalam mendorong kelangsungan hidup (dan penyebaran) virus di lingkungan.
Analisis yang dilakukan menyoroti bahwa nilai indeks SHAP tertinggi yang terkait dengan titik embun terjadi pada suhu rendah dan tingkat kelembapan relatif tinggi, terutama saat titik embun rendah (biasanya pada bulan-bulan yang lebih dingin). Kesimpulan ini semakin ditekankan oleh evaluasi risiko relatif yang terkait dengan waktu jeda: penerapan model DLNM, pada kenyataannya, mengungkapkan bahwa, baik untuk pasien yang dirawat di rumah sakit dengan gejala maupun untuk kasus positif per 100.000 penduduk, risiko penyebaran COVID-19 terbesar terjadi saat nilai titik embun rendah.
Meskipun penyelidikan ini baru dilakukan di tiga wilayah di Italia saja, dan perkembangan di masa mendatang dengan analisis tambahan dapat mengonfirmasi hipotesis ini, studi ini memberikan wawasan penting tentang penyebaran COVID-19, dengan menekankan pentingnya mempertimbangkan faktor meteorologi dalam merancang strategi pencegahan dan pengendalian penyebaran virus, bahkan untuk patologi lain, khususnya yang melibatkan sistem pernapasan.